先說在前面…不是鼓勵盜版, 也不是鼓勵去操掛人家網站, 這篇的出發點是單純好玩…起因是, 雖然現在大多數的人看漫畫都用布卡來看, 但布卡也不是所有漫畫都找的到, 上次聽到有人說布卡找不到某某漫畫, 就Google了一下, 總還是會有些網站有, 而且發現, 這些網站的結構都差不多, 所以就想說來寫個東西抓這些圖檔離線來看, 以下的技巧當然不只可以用在這用途上…
抓取這類的非結構性資料的網站, 最直覺的方式就是把html抓回來解析, 不過這類型的網站, 為了保護資料, 所以很多東西都寫在javascript中, 這樣光解析靜態的html是不夠的, 還要去搞懂怎從他程式中抓到想要的資料是很累人的, 不過, 不管用了多少html, javascript, css的技巧, 最終還是得把整個頁面畫到browser才能讓使用者看到, 也就是如果在瀏覽器上, 到最後還是會有一個完整的DOM tree讓我們從某個節點取得我們想要的資料
不過, 這樣聽起來好像還是工程浩大, 還得綁個瀏覽器? 其實不用, 只要靠 phantom.js 就好
PhantomJS is a headless WebKit scriptable with a JavaScript API. It has fast and native support for various web standards: DOM handling, CSS selector, JSON, Canvas, and SVG.
反正呢….就是…這個可以拿來做這用途, 把它當一個scriptable沒畫面的Browser就對了
接下來我們拿"看漫畫"(http://tw.seemh.com/)這網站來當個範例
以"夜王"這部漫畫(http://tw.seemh.com/comic/6563/)來說, 從url可以猜到6563是他的ID, 而進入這個link之中, 有一堆單行本的列表, 所以第一個打算當然是用程式取的這些列表跟他的url囉, 所以打開Chrome的開發人員工具
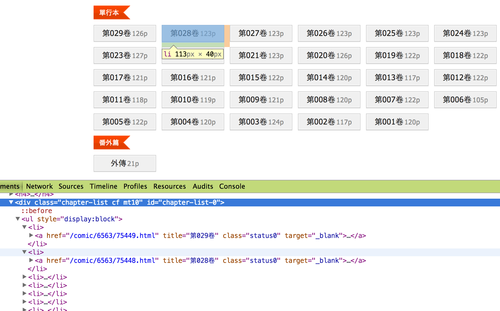
從這上面可以看到, 這些連結有個共通點, 就是它們的class都是"status0", 為了證實這一想法, 切到console用"document.querySelectorAll(’.status0’)“來測試一下:
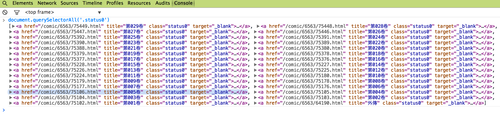
Bingo!果然如此, 因此這就適合我們拿phantom.js來抓取了url, 因此我們可以採用以下的code (書名的class是book-title)
function getComics() {
var url = 'http://tw.seemh.com/comic/6563/';
page.open(url, function (status) {
var book_title = page.evaluate(function() {
var title = document.querySelector('.book-title');
return title.innerText;
});
console.log(book_title);
var elements = page.evaluate(function() {
var elems = document.querySelectorAll('a.status0');
var titles = [];
for(var i=0;i<elems.length;i++) {
titles.push({title:elems[i].title, url:elems[i].href});
}
return titles;
});
elements.forEach(function(arg, i) {
console.log(arg.title);
});
console.log('end');
phantom.exit();
});
};
Phantom.js可以直接用page.evaluate()對網頁執行javascript, 因此我們可以在這之內用document.querySelector來取得我們所需要的節點
接下來進入每本單行版的頁面, 如 http://tw.seemh.com/comic/6563/75102.html , 這邊我們有興趣的是, 到底有幾頁, 以及, 圖片到底在哪?
所幸這也很簡單
頁面的資訊就在上方那條, 有個下拉選擇的部份, 用同樣的方法我們可知, 它的id是"pageSelect”, 因此, 我們可以以下面的方式取的頁面數量:
nPages = page.evaluate(function() {
return document.getElementById('pageSelect').length;
});
而圖片的id則是"mangaFile", 透過同樣的方式也可以取得檔名
雖然在phantom.js可以用page.render來直接存圖檔, 但缺點是不能指定檔名跟存放位置, 所以我這邊的作法是直接輸出成shell script, 使用curl來做圖形抓取的動作
完整的範例在: https://github.com/julianshen/comic_grabber (沒完全測試, 可能有bug)
補充一點, phantom.js有個bug, 在evaluate裡的array如果傳到外面來用的話, 使用pop(), shift()會出問題, 這也就是範例中, 要先把array給變成JSON string再轉回去的原因