在現代的網頁開發中,JavaScript 驅動的動態網站變得越來越普遍,這對使用傳統 HTML 解析的爬蟲工具帶來了挑戰。傳統的方法不再適用,因為網頁的內容必須在執行 JavaScript 後才會生成。解析這種網站需要更多前端的知識。
chromedp 是一個用 Go 語言編寫的工具包,它通過 Chrome 的 DevTools 協議進行無頭瀏覽器(Headless Browser)自動化,使開發者能夠程式化地控制 Chrome 瀏覽器,方便地爬取和解析動態生成的內容。本文將介紹如何使用 chromedp 來建立一個簡單的網路爬蟲。
基本原理
chromedp 主要通過與 Chrome 瀏覽器的 DevTools 協議通信來實現其功能。這使得開發者可以模擬使用者操作,例如導航到網頁、點擊按鈕、填寫表單以及提取動態載入的內容。這些操作在無頭模式(Headless mode)下進行,瀏覽器界面不可見,從而提高效能和資源利用效率。透過這種方式,chromedp 可以處理傳統 HTML 解析工具無法處理的情況,特別是在處理動態生成的內容時。
簡單範例程式碼
以下是一個使用 chromedp 爬取網站資料的簡單範例,這個範例展示了如何導航到一個網站、選擇一些元素、提交表單並提取所需的數據:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/chromedp/chromedp"
)
func main() {
// 建立 context
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
// 分配瀏覽器
ctx, cancel = chromedp.NewExecAllocator(ctx, chromedp.DefaultExecAllocatorOptions[:]...)
defer cancel()
// 建立具有timeout 30秒的 context
ctx, cancel = context.WithTimeout(ctx, 30*time.Second)
defer cancel()
// 執行任務
var res string
err := chromedp.Run(ctx,
chromedp.Navigate("https://example.com"),
chromedp.WaitVisible(`body`, chromedp.ByQuery),
chromedp.SendKeys(`input[name="q"]`, "chromedp", chromedp.ByQuery),
chromedp.Click(`input[type="submit"]`, chromedp.ByQuery),
chromedp.WaitVisible(`#result-stats`, chromedp.ByQuery),
chromedp.Text(`#result-stats`, &res, chromedp.ByQuery),
)
if err != nil {
log.Fatal(err)
}
fmt.Println("Search Result Stats:", res)
}
在這個範例中,我們建立了一個 chromedp 任務,它會導航到 example.com,等待頁面載入完成後,在搜尋框中輸入 “chromedp”,點擊提交按鈕,然後等待搜尋結果統計資訊的元素可見,並提取該資訊。這是一個基本範例,展示了如何使用 chromedp 進行基本的網頁互動和數據提取。你可以根據需要擴展此範例以實現更複雜的爬蟲功能。
接下來我們用一個更實用的案例來實作,以下範例展示如何使用 chromedp 爬取中華職棒(CPBL)的賽程表,此網站由 Vue.js 實作。
解析文件
中華職棒賽程網站的網址是 https://cpbl.com.tw/schedule。首先,我們用檢視網頁原始碼(View page source)來看看,可以發現裡面找不到任何賽程資料。另外,我們還能發現這段程式碼:
var app = new Vue({
el: "#Center",
mixins: [mixin],
以及另一段用來取得賽程資訊的程式:
$.ajax({
url: '/schedule/getgamedatas',
type: 'POST',
data: filterData,
headers: {
RequestVerificationToken: 'PzmpuUOvS4z2zH_QhwgFQYTzVC82b0n2QH30wEOJ12kOWA6zeq0Yn7_6d2v_o-ZTWuNPe3HjrqsMqAHp9sL0F5KB4KM1:5jgubJ0tGDTK3cLm2JU7_bCw9JqLOG8j8yeNiWDhR4nnTACLXerDqmzB5chZv-iqY8m1ep6IirI3hAwRCPfNTU6jO_E1'
},
success: function(result) {
if (result.Success) {
_this.gameDatas = JSON.parse(result.GameDatas);
_this.getGames();
}
},
error: function(res) {
console.log(res);
},
complete: function () {
$("body").unblock()
}
});
很明顯這是一個用 Vue.js 寫的網頁。我們當然可以試著去打它的 API,但看到那串 Token,可能做了某些保護,使用 chromedp 的方式可能更簡單。
那怎麼開始解析呢?用 ChatGPT 或許是一個好方法,打開 Chrome 的開發人員工具,在 Elements 那邊可以看到已經是最終的網頁結果,試著把它存成一個檔案並詢問 ChatGPT:
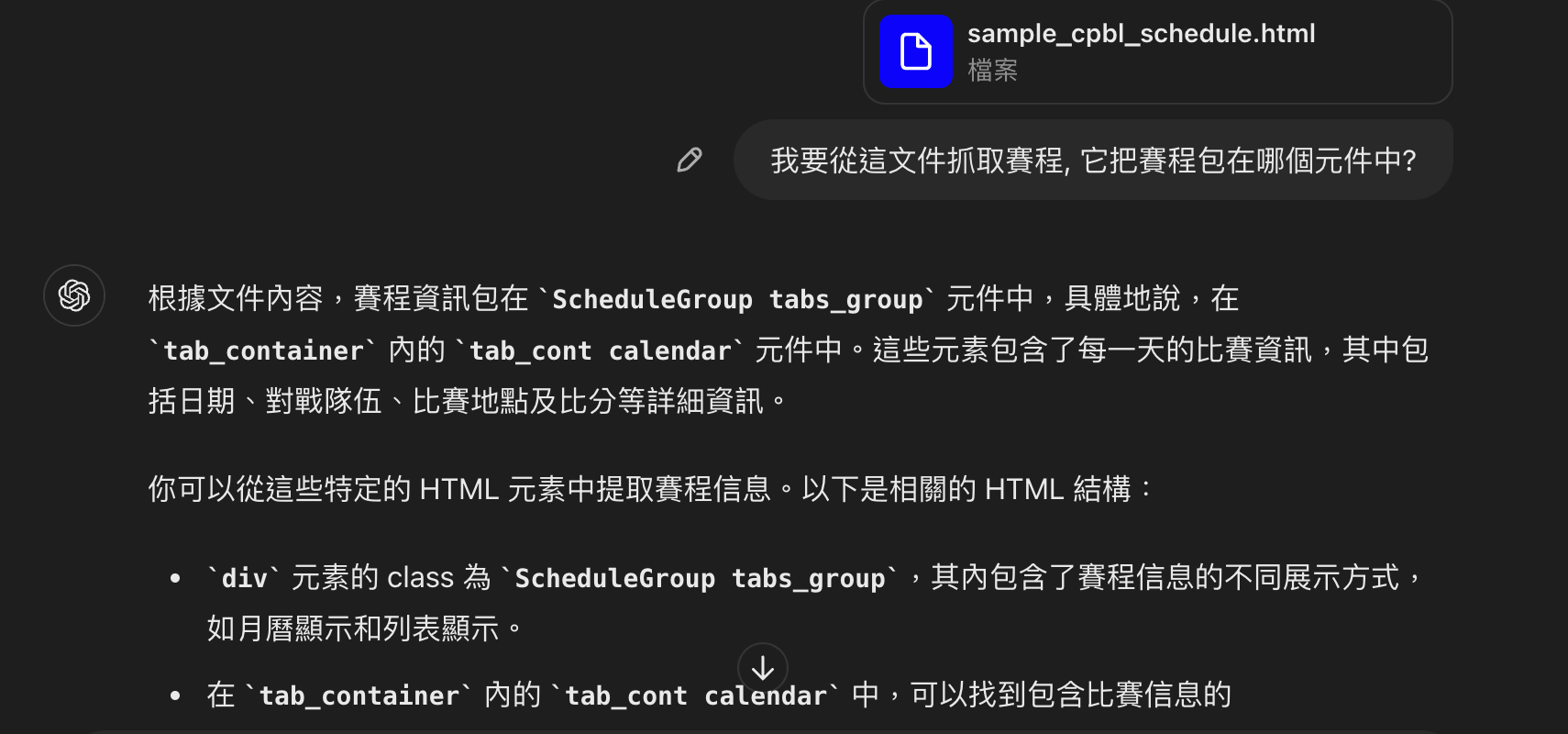
資料結構也可以順便請它設計一下:
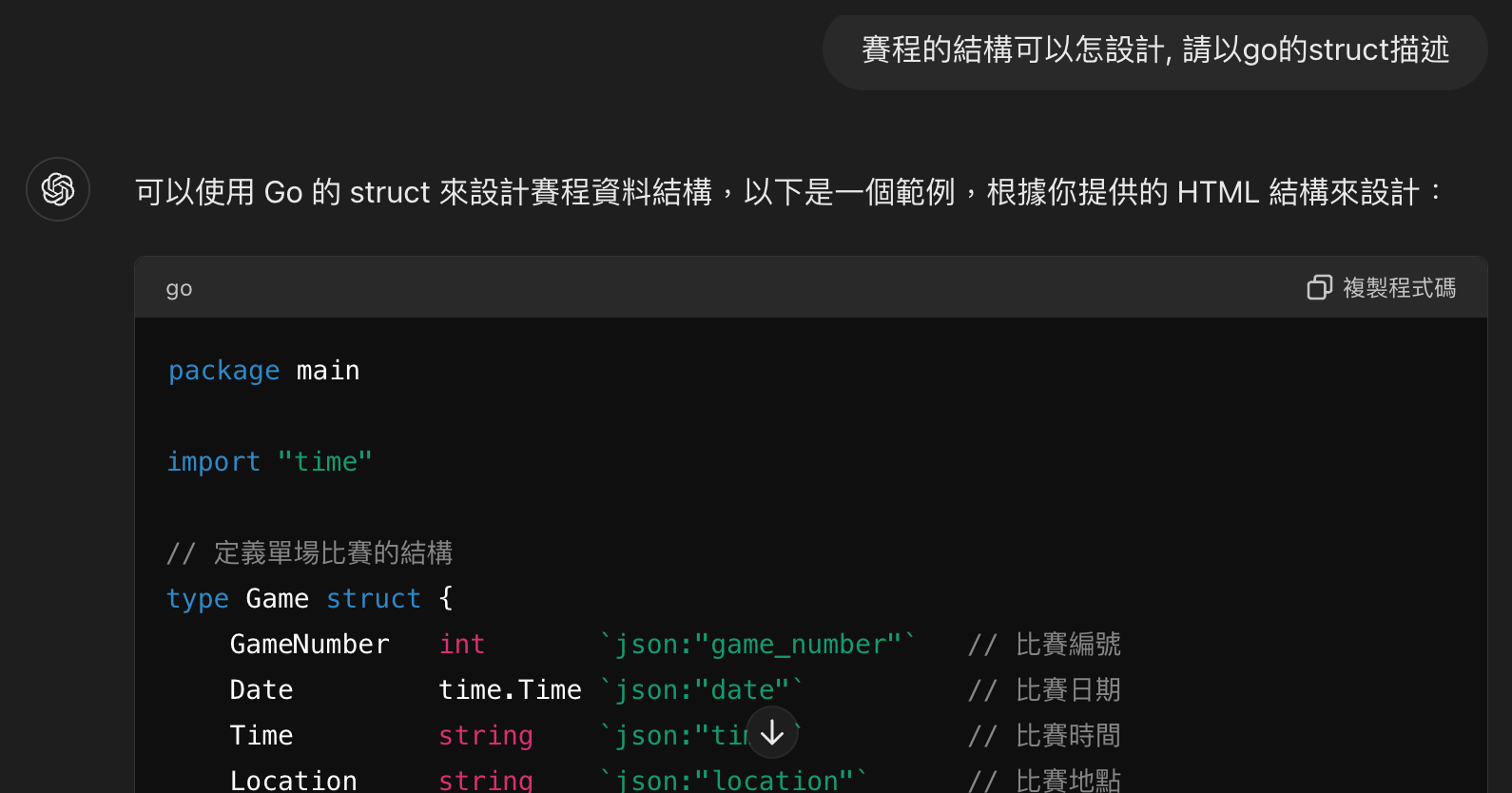
這當然只能當作一開始的參考,後面也可以請它幫你直接寫程式。不過,我試了一下,它寫出來的只能當範例,不能產出正確的結果,但拿來作為基礎修改其實也不錯用。
先定義一下需求,我們需要寫一個函數,可以輸入年月和比賽種類來取得賽程資訊。
依照這些資訊,先來寫一個比較粗略的版本來實驗一下:
type Game struct {
No int `json:"no"`
Year int `json:"year"`
Month int `json:"month"`
Day int `json:"day"`
Home string `json:"home"`
Away string `json:"away"`
Ballpark string `json:"ballpark"`
}
func getGameNodes(nodes *[]*cdp.Node) chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
ctxWithTimeout, cancel := context.WithTimeout(ctx, 900*time.Millisecond)
defer cancel()
chromedp.Nodes("div.game", nodes).Do(ctxWithTimeout)
for _, n := range *nodes {
dom.RequestChildNodes(n.NodeID).WithDepth(6).Do(ctxWithTimeout)
}
return nil
})
}
func selectMonth(month string) chromedp.QueryAction {
return chromedp.SetValue("div.item.month select", month, chromedp.ByQueryAll)
}
func selectYear(year string) chromedp.QueryAction {
return chromedp.SetValue("div.item.year select", year, chromedp.ByQueryAll)
}
func selectGameType(gtype string) chromedp.Action {
return chromedp.SetValue("div.item.game_type select", gtype, chromedp.ByQueryAll)
}
func fetchGamesByMonth(ctx context.Context, year string, month string) ([]Game, error) {
chromedp.Run(ctx, selectMonth(month),
chromedp.WaitVisible("div.ScheduleGroup"),
chromedp.Sleep(800*time.Millisecond),
)
var nodes []*cdp.Node
var mn string
chromedp.Run(ctx,
chromedp.Text(".date_selected .date", &mn),
getGameNodes(&nodes),
)
var games []Game = make([]Game, len(nodes))
for i, node := range nodes {
games[i].No, _ = strconv.Atoi(strings.Trim(node.Children[0].Children[0].Children[0].Children[1].Children[0].NodeValue, " "))
games[i].Ballpark = node.Children[0].Children[0].Children[0].Children[0].Children[0].NodeValue
games[i].Year, _ = strconv.Atoi(year)
monthInt, _ := strconv.Atoi(month)
games[i].Month = monthInt + 1
dataDate := node.Parent.Children[0].AttributeValue("data-date")
day, _ := strconv.Atoi(dataDate)
games[i].Day = day
games[i].Away = node.Children[0].Children[0].Children[1].Children[0].Children[0].AttributeValue("title")
games[i].Home = node.Children[0].Children[0].Children[1].Children[2].Children[0].AttributeValue("title")
}
return games, nil
}
這個版本程式碼很粗略但可用,主要使用 NodeValue 和 AttributeValue 來取值。這種方法的問題在於,這些 chromedp 呼叫每一個都需要與 Chrome 通信,而這是通過 Chrome DevTools Protocol 來實現的。Chrome DevTools Protocol 使用 WebSocket 進行通信,這樣頻繁來回不僅效率低,穩定性也較差。
下面這個範例是從 ChatGPT 學來的方法再優化的:
// FetchSchedule fetches the schedule from CPBL website based on the year, month, and game type
func FetchSchedule(year int, month int, gameType string) ([]GameSchedule, error) {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var schedules []GameSchedule
// Define the URL
url := "https://cpbl.com.tw/schedule"
// Run chromedp tasks
err := chromedp.Run(ctx,
chromedp.Navigate(url),
chromedp.WaitReady(`.ScheduleTableList`), // Wait for year select to be ready
chromedp.Evaluate(fmt.Sprintf("document.querySelector('#Center').__vue__.filters.kindCode = '%s'", gameType), nil),
chromedp.Evaluate(fmt.Sprintf("document.querySelector('#Center').__vue__.calendar.year = %d", year), nil),
chromedp.WaitReady(`.ScheduleTableList`), // Wait for year select to be ready
chromedp.Evaluate(fmt.Sprintf("document.querySelector('#Center').__vue__.calendar.month = %d", month-1), nil),
chromedp.Evaluate(`document.querySelector('#Center').__vue__.getGameDatas()`, nil), // Wait for table to be visible
chromedp.Sleep(2*time.Second), // Wait for table to load
chromedp.Evaluate(`
(() => {
let schedules = [];
document.querySelectorAll('.ScheduleTable tbody .date').forEach(dateDiv => {
let date = dateDiv.innerText.trim();
let parent = dateDiv.parentNode;
parent.querySelectorAll('.game').forEach(gameDiv => {
let location = gameDiv.querySelector('.place') ? gameDiv.querySelector('.place').innerText.trim() : '';
let game_no = gameDiv.querySelector('.game_no') ? gameDiv.querySelector('.game_no').innerText.trim() : '';
let away_team = gameDiv.querySelector('.team.away span') ? gameDiv.querySelector('.team.away span').title.trim() : '';
let home_team = gameDiv.querySelector('.team.home span') ? gameDiv.querySelector('.team.home span').title.trim() : '';
let score = gameDiv.querySelector('.score') ? gameDiv.querySelector('.score').innerText.trim() : '';
let remark = gameDiv.querySelector('.remark .note div') ? gameDiv.querySelector('.remark .note div').innerText.trim() : '';
schedules.push({ date, location, game_no, away_team, home_team, score, remark });
});
});
return schedules;
})()
`, &schedules),
)
if err != nil {
return nil, err
}
return schedules, nil
}
這個版本大量使用 chromedp.Evaluate 來內嵌 JavaScript 程式碼直接在網頁執行。這樣可讀性更好,且避免了頻繁與 Chrome 通信。這種方法更高效且穩定。