在離職前一周研究的一個小題目, 說小其實也蠻難搞的, 搞到這兩天重新看, 才釐清完整做法
難搞的原因有幾個, 雖然OpenTelemetry有支援gRPC, 但對於 Thrift 就沒人做相關的支援了, 再來就是系統環境跨了nodejs和Finagle/Scala兩種平台, Thrift 是用在這兩者之間的溝通, Finagle雖是有支援ZipKin做分散式追蹤, 但那僅限於Finagle client呼叫Finagle server的部分才有支援在這之間傳遞追蹤資訊, 跨nodejs (client) 到 Finagle (server), 這邊也一樣找不到啥資訊
所以這邊主要會想做到的:
- 自動插入追蹤的程式碼
- 在 Thrift client/server 間傳遞追蹤資訊 (client/server不同平台)
大致上的原理有做過些小實驗, 確定應該可行, 只是懶得把整套完整做好就是了
分散式追蹤 Distributed Tracing
在大型的分散式系統, 一個從使用者端來的request通常都會被分發到不同的系統去做處理, 尤其現在大多流行微服務(Micro services)架構, 這種狀況相當的常見, 當問題發生的時候, 到底甚麼時間點在哪個系統, 碰到甚麼事, 要追查原因便得從這麼多系統分散且看不出關聯性的log去想辦法分析出來, 因此導入分散式追蹤, 就是為了解決這問題
最早出現應該是Google內部使用的Dapper, 也有發表相關的論文, 開源的部分, 早期又有Twitter的ZipKin和Uber的Jaeger, 前面有提到的Finagle, 由於也是Twitter開源出來的應用程式框架, 所以Finagle出廠就支援ZipKin也是理所當然的
後來又出現想要大一統的OpenTracing和OpenCensus, 這兩個後來又被大一統到這邊所要提到的OpenTelemetry
做Distributed Tracing雖然對追問題會有幫助, 但要導入並不見的容易, 先是要在所有要追蹤的插入追蹤程式碼, 對於既有系統的改動幅度自是不小, 此外, 早期, 不管是ZipKin和Uber的Jaeger還是Jaeger考量的主要還是REST API的架構, REST是透過HTTP傳輸的, 因此在設計上, 就可以透過HTTP header帶追蹤相關資訊, 但在一個複雜的分散式系統, 可能包含不同的通訊協定, 像是REST, GraphQL, gRPC, Thrift, 或是呼叫資料庫之類的, 不見得都是透過HTTP, 那怎麼傳遞追蹤資訊就是個問題, 跨系統間如果無法分享追蹤資訊, 那也是白搭
OpenTelemetry
OpenTelemetry其實也不是只有支援Distributed Tracing, 它能處理的資料型態, 主要就有下面這幾種:
- Traces
- Metrics
- Logs
也就是說除了追蹤資訊, 它也囊括了系統狀態跟Logs, 另外也支援很多不同語言, 算是野心蠻大的, 這邊來看一下它的架構:

主要它包含了兩部分, 一個是各程式語言使用的程式庫 - OT Library, 另一個是蒐集資訊的Collector, 而Collector是這樣的:

Collector包含了Receiver, Processor, Exporter, 這架構讓它有能力相容/支援不同的系統, 所以像是Finagle這種本來就有支援ZipKin的, 其實只要把原本倒到ZipKin的資料轉倒到OpenTelemetry的Collector就好, 這邊算是好解決, 如果系統是跑在K8S這類的環境上的話, 也可以考慮把Collector 當成sidecar來佈署
而各程式語言的程式庫的部分, 方便的是在某些程式語言有支援所謂的auto instrumentation, 針對有支援的程式庫或是框架, 可以在不寫任何程式碼或是寫少少的程式碼, 就可以達到分散式追蹤的目的(聽來有點玄), 像是Java就支援了這些(請參考連結), 而Javascript有這些(請參考連結)
但畢竟沒有甚麼是萬能的, 沒支援的還是得靠自己手動插追蹤的程式碼, 或是想辦法支援, 像是這篇正題的部分, 這邊想要追蹤從nodejs呼叫Finagle的部分, 就沒辦法使用現成的 (實際狀況更複雜, nodejs本身是graphql server, Finagle server又可能呼叫ElasticSearch或Kafka, 如果想全部串起來, 不算小, 這邊主要針對 nodejs <-> Finagle部分)
在Node.JS下用OpenTelemetry做Tracing
基本使用上其實相當簡單, 可以參考這個連結, 先用一個小範例來解釋:
const { HttpInstrumentation } = require('@opentelemetry/instrumentation-http');
const { GrpcInstrumentation } = require('@opentelemetry/instrumentation-grpc');
const { ExpressInstrumentation } = require('@opentelemetry/instrumentation-express');
const { ConsoleSpanExporter, SimpleSpanProcessor } = require('@opentelemetry/tracing');
const { NodeTracerProvider } = require('@opentelemetry/node');
const { registerInstrumentations } = require('@opentelemetry/instrumentation');
const provider = new NodeTracerProvider();
provider.addSpanProcessor(new SimpleSpanProcessor(new ConsoleSpanExporter()));
provider.register();
registerInstrumentations({
instrumentations: [
new HttpInstrumentation(),
new GrpcInstrumentation(),
new ExpressInstrumentation()
],
});
以這範例來說, 它打開了支援http, grpc, express等程式庫的auto instrumentation, 亦即在你的程式中如果有用到這幾個程式庫, 它會自動加上對應的追蹤程式碼, 你不用額外做任何事, 從client到server都處理好, 或是你也可以像文件中用:
// This will automatically enable all instrumentations
registerInstrumentations({
instrumentations: [getNodeAutoInstrumentations()],
});
getNodeAutoInstrumentations()包含了底下這幾種的資源:
@opentelemetry/instrumentation-dns': DnsInstrumentation@opentelemetry/instrumentation-express': ExpressInstrumentation@opentelemetry/instrumentation-graphql': GraphQLInstrumentation@opentelemetry/instrumentation-grpc': GrpcInstrumentation@opentelemetry/instrumentation-http': HttpInstrumentation@opentelemetry/instrumentation-ioredis': IORedisInstrumentation@opentelemetry/instrumentation-koa': KoaInstrumentation@opentelemetry/instrumentation-mongodb': MongoDBInstrumentation@opentelemetry/instrumentation-mysql': MySQLInstrumentation@opentelemetry/instrumentation-pg': PgInstrumentation@opentelemetry/instrumentation-redis': RedisInstrumentation
建議如果沒要追蹤這麼多東西的話, 還是一個個加就好, 畢竟資訊多雜訊也多
在這邊:
const provider = new NodeTracerProvider();
provider.addSpanProcessor(new SimpleSpanProcessor(new ConsoleSpanExporter()));
這兩行是建立Trace Provider, 告訴它要用哪個Processor或哪個Exporter去處理追蹤資訊, 這跟前面提到的Collector的架構上大致類似, 這邊用的是Consle exporter,也就是追蹤資訊會被直接印在螢幕上, 如果想輸出到ZipKin或是Jaeger就用相對應的Exporter就可以了, 或者也可以用OTLP的Exporter直接輸出到OpenTelemetry的collector
但這是在有支援的狀況下, 如果沒有呢? 就得手動去插了, 看一下下面這範例:
const opentelemetry = require('@opentelemetry/api');
const tracer = opentelemetry.trace.getTracer('example-basic-tracer-node');
// Create a span. A span must be closed.
const span = tracer.startSpan('main');
doWork();
// Be sure to end the span.
span.end();
這是簡單追蹤一個程序的方法, 在這範例是doWork(), 這邊就可以追蹤從startSpan到end之間的耗費的時間了, 針對沒有支援auto instrumentation, 或是你想額外在你程式內追蹤些別的, 那就得用這種方式在需要追蹤的地方加入這些
很不幸的, 目前不管哪個語言, Java, Javascript, 都沒支援Thrift相關的, 所以如果要追蹤 Thrift, 可能就得是這樣, 除了可能需要改不少地方外, 插入這些code其實也不太好看啦 :p
追蹤 Thrift RPC
Thrift算是一個有點歷史的RPC框架(framework)了, 雖然應該還有不少大公司像是Twitter, Facebook, LINE, LinkedIn還有在使用, 不過現在大家大部分應該是比較常用比較潮的gRPC, 比較少用Thrift了, 所以在OpenTelemetry這種新東西找不到支援應該也情有可原
為了比較好確認解決這問題的概念是怎樣, 這邊先把問題/架構先簡化如下:
- Thrift client: 跑在nodejs下, 以typescript開發
- Thrift server: 跑在Twitter Finagle框架, 以scala開發 (事實上, 我也有實做一個go版本的server, 不過先不在這討論)
所以這邊會需要知道的是:
- client呼叫每個Thrift call需要的時間
- 在server上每個call又對應哪些呼叫或花費
用以下ZipKin這張圖來當範例, 就可以這樣一層層追蹤下去
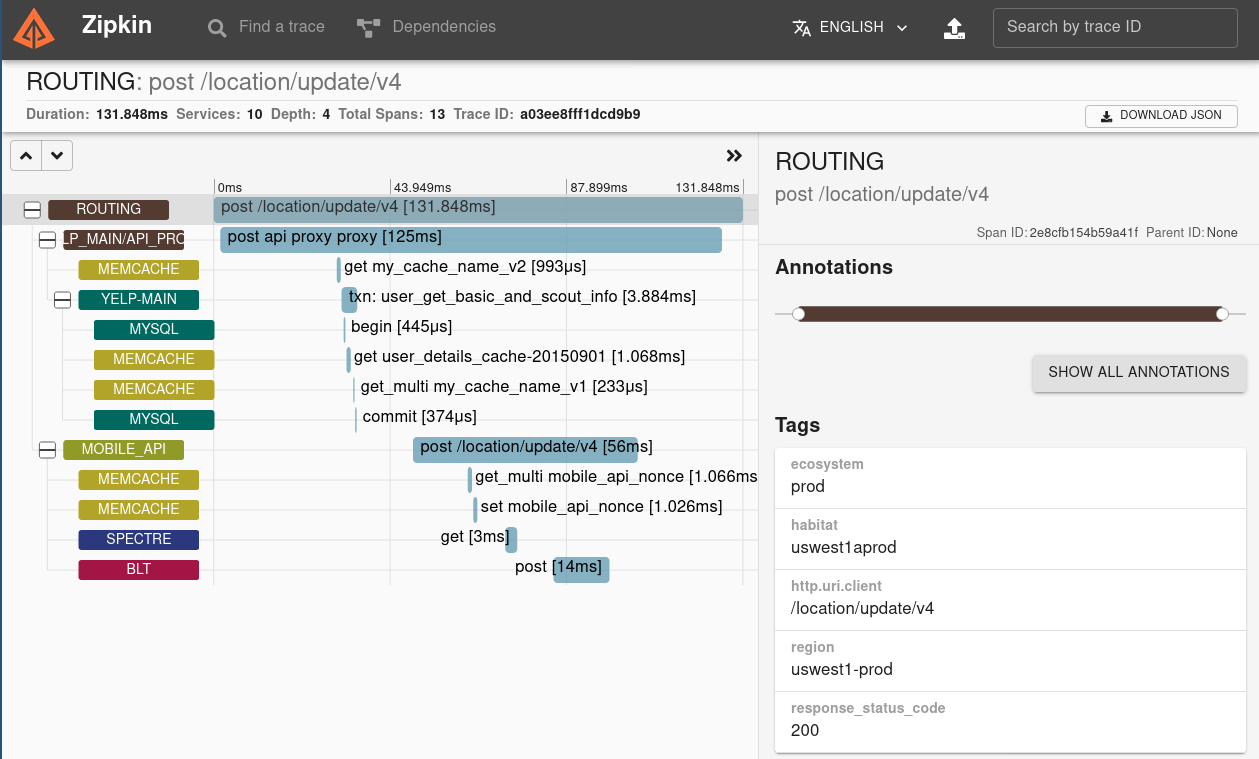
Client部分雖然可以使用手工插入tracing相關的程式碼, 但當然還是做成自動的最好, 而且client必須要可以把相關的trace ID, span ID給傳遞到server, 要不然線索就會斷掉了
為了達到這目標, 首先我們先來看一下Thrift從Client到Server經過哪些地方:
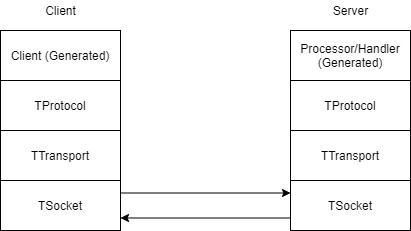
從這圖看來, 可能可以插入追蹤碼的點可以是產生出來的Client code或是TProtocol的位置(為何?後面再提)
在前面我也寫了一篇"在nodejs使用typescript呼叫thrift client“裡面有提到利用thrift -r --gen js:ts smaple.thrift來產生nodejs用的client code
以下面這個Thrift IDL來當範例:
namespace java sample.thrift
#@namespace scala sample.thrift
namespace go rpc
service SampleService {
string hello(1: i64 a, 2: i64 b)
void hello2()
}
用thrift -r --gen js:ts sample.thrift就可以產生四個檔案, 分別是:
- sample_types.js
- sample_types.d.ts
- SampleService.js SampleService的定義
- SampleService.d.ts SampleService的javascript實作(Client + Processor)
再仔細去看SampleService.js, 以hello這個method為例, 你會發現在 SampleServiceClient 裡關於hello的部分有三部分:
hello(a, b, callback)實際給程式呼叫的介面, 這邊回傳是個Promisesend_hello(a, b)會由hello去呼叫, 實際上負責傳遞呼叫的相關資訊recv_hello(input,mtype,rseqid)當send_hello送出呼叫資訊到server後, Connection會等到Server回應後, 會呼叫 recv_functionname, 去處理回傳回來的資訊
另外在 send_hello 的一開始會去呼叫 output.writeMessageBegin('hello', Thrift.MessageType.CALL, this.seqid()); , 這邊的output是TProtocol, 在呼叫 recv_hello 之前則是會呼叫 input.readMessageBegin() 這邊也可以得到呼叫的method的資訊
由上面的線索看來, 可以插入追蹤程式碼可能的幾個點:
hello(a, b, callback)的一開始到Promise結束send_hello(a, b)到recv_hello(input,mtype,rseqid)的結束writeMessageBegin到readMessageBegin
這邊問題在於 hello, send_hello, recv_hello都是由thrift這個指令產出的, 而writeMessageBegin, readMessageBegin則是在thrift的程式庫內
我們要怎樣在裡面插入追蹤的程式碼?或是有沒辦法做到auto instrumentation那樣?
Javascript auto instrumentation in OpenTelemetry
OpenTelemetry其實是有開放介面給大家去開發相關的auto instrumentation, 不過這一塊實在看得有點頭痛, 沒文件, 又不好懂, 我最後沒採用這方法實作, 但因為在這邊花了不少時間, 還是簡單的介紹一下
前面有提到的有許多auto instrumentation的實作, 都是被放到 opentelemetry-js-contrib/plugins/node, 也就是說你可以用一樣的方法做出自己的auto instrumentation
其架構的原始碼可以參考opentelemetry-js/packages/opentelemetry-instrumentation, 至於如何去寫一個plugin則可以參考 這篇
基本的plugin大致上像這樣:
import type * as mssql from 'mypackage';
import {
InstrumentationBase,
InstrumentationConfig,
InstrumentationModuleDefinition,
} from '@opentelemetry/instrumentation';
type Config = InstrumentationConfig ;
export class MYPlugin extends InstrumentationBase<typeof mypackage> {
protected init(): void | InstrumentationModuleDefinition<any> | InstrumentationModuleDefinition<any>[] {
throw new Error('Method not implemented.');
}
}
Plugin必須繼承自InstrumentationBase, 最好的範例應該是 http的instrumentation的實作, 在這裏面, 你會看到像是:
this._wrap(
moduleExports,
'request',
this._getPatchOutgoingRequestFunction('http')
);
這目的就是為了把原本的函數替換成包裝過有插追蹤碼的程式, 原理其實很容易理解, 而它是用了 shimmer 這個package, 來達到這個替換的目的, 實際上去看 shimmer, 也並不是一個很複雜的做法就是了
本來我是考慮寫一個plugin來處理Thrift client的部分, 原本的考量點是, 由於 shimmer 需要先知道method的名字才能替代, 所以 hello, send_hello, recv_hello 就不適合用來做包裝, 畢竟要做也是要做一個通用的, 不然試作後, 單純包裝 hello 其實算容易 (在呼叫原版本hello前先startSpan, 並把span.end包裝到回傳的Promise), 所以適合用在這邊的可能是包裝 TProtocol.writeMessageBegin, TProtocol.readMessageBegin ,不過這邊一直弄不成功, 可能也沒搞很懂instrumentation plugin, 後來又發現更簡便的做法就先放棄
從 thift generator 下手
在用 shimmer 包裝 hello 時, 發現了一個問題, 由於我是用 typescript 而非javascript 在做這個實驗, typescript會去做型別檢查, 本來Javascript版本的 hello 的回傳是Promise, 但我在定義wrapped function的時候, 回傳型別設成
Promise<string> 則是會報錯, 結果實際上去看產生的程式碼:
hello(a: Int64, b: Int64): string;
這完全是錯的, 也就是由Apache thrift這個工具產生的typescript是有問題的
想到在Scala中, 產生Thrift相關程式碼是用scrooge並不會去用官方Apache thrift的工具, typescript會不會也有像scrooge這工具? 結果就找到了creditkarma/thrift-typescript
這個專案也是蠻有趣的, 它是透過 Typescript compiler API, 把Thrift IDL完全轉成typescript程式碼, 跟官方工具不同的地方是, 它產生的是純typecsript實做, 而非javascript實做搭配typescript定義, 因此產生的程式碼也好讀多了
所以我想, 何必一定糾結在auto instrumentation, 從code generator 去修改也是一個可行的做法, 要做到這件事, 那就要先看看, 我們預期它產生怎樣的程式碼, 於是我就去修改產生的程式碼來實驗, 像這樣:
export class Client {
public _seqid: number;
public _reqs: {
[name: number]: (err: Error | object | undefined, val?: any) => void;
};
public output: thrift.TTransport;
public protocol: new (trans: thrift.TTransport) => thrift.TProtocol;
public tracer:opentelemetry.Tracer;
private serverSupportTracing: boolean;
constructor(output: thrift.TTransport, protocol: new (trans: thrift.TTransport) => thrift.TProtocol) {
this._seqid = 0;
this._reqs = {};
this.output = output;
this.protocol = protocol;
this.tracer = opentelemetry.trace.getTracer('SampleServiceClient');
this.serverSupportTracing = false;
}
public incrementSeqId(): number {
return this._seqid += 1;
}
public hello(a: Int64, b: Int64): Promise<string> {
const requestId: number = this.incrementSeqId();
const span:opentelemetry.Span = this.tracer.startSpan("hello");
return new Promise<string>((resolve, reject): void => {
this._reqs[requestId] = (error, result) => {
delete this._reqs[requestId];
if (error != null) {
reject(error);
}
else {
resolve(result);
}
span.end();
};
this.send_hello(a, b, requestId);
});
}
}
這一段程式碼是截自 creditkarma/thrift-typescript 從我的IDL產生的程式碼, 加上了tracer跟span, startSpan和span.end就插在hello裡面
這一段先用手工插入實驗後沒問題, 接下來我們就可以去改 creditkarma/thrift-typescript 讓程式自動去產生
由於這邊牽涉多一點, 我就不一一解釋, 貼上我修改的commit, 大家有興趣可以參考 : https://github.com/julianshen/thrift-typescript/commit/5f2ebeb85f6e639be11d5184f5470ca8d4d466b9
這樣一來, 產生我們要的client code就沒啥問題了
傳遞追蹤資訊
前面有提到Finagle有支援Zipkin Tracing, 只有client和server都是Finagle才可以在Thrift間傳遞追蹤資訊, 那實際上Finagle又是怎做的呢? 它的做法是在Thrift的通訊協定上做了一些小修改, 先來看看底下這三張圖
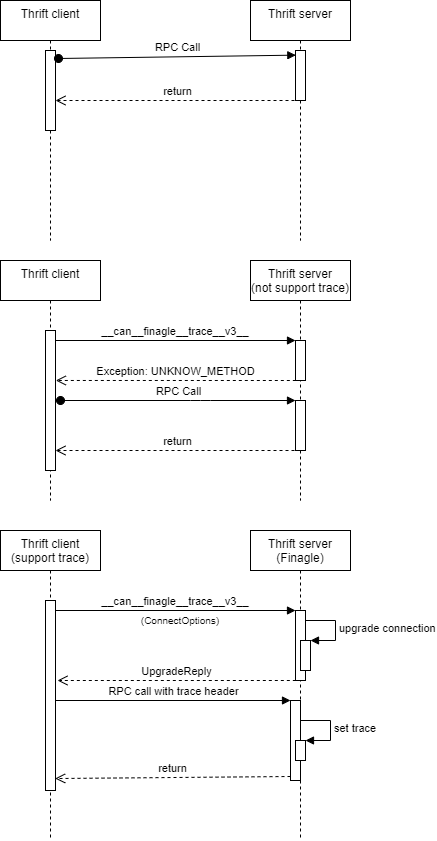
第一張是通常狀況, 在兩端都不支援傳遞追蹤資訊, 或是Client不支援, 就是走正常的路線, 第二三張則是在Client有支援(Finagle client), client會先送__can__finagle__trace__v3__這個呼叫確認server有支援, server如果有支援的話, 就會回傳正確的結果, 如果沒支援則會是 UNKNOW_METHOD
Client在確認server有支援後, 後面的request就會先多帶一個header包含Tracing相關的資訊了
這部分, 我目前也只實做go版本的server, client版本尚未做, 這邊會需要做的部份包含:
- 呼叫
__can__finagle__trace__v3__確認是否支援tracing - 將client端的tracing資訊帶入相關的header中
如果client是用OpenTelemetry, 而server這邊是用Finagle加zipkin的話, 就得要注意Trace ID, Span ID的轉換, 這兩邊用的長度跟型別有點不太一樣, 轉換的範例如下:
func UInt64ToTraceID(high, low uint64) pdata.TraceID {
traceID := [16]byte{}
binary.BigEndian.PutUint64(traceID[:8], high)
binary.BigEndian.PutUint64(traceID[8:], low)
return pdata.NewTraceID(traceID)
}
只要在把這整段整合到code generator, 應該就可以大功告成了
雖然一開始覺得是個小題目, 沒想到居然讓我用這麼大篇幅介紹, 而且全部實做還沒完成, 看來是有點太過低估了