在之前一篇寫用Hugo打造blog有提到, 寫了一個小工具來產生open graph image, 但由於這個是一個command line工具, 而我又是把它放在 git pre-commit 去觸發並寫回檔案, 感覺不是那麼乾淨, 因此我又有另一個想法想把它寫成一個服務, 順便又思考了一下, 怎樣的圖片比較適合OG(Open Graph)
為什麼要設定 Open Graph Image
這邊並沒有要探討Open Graph是什麼, 怎麼去使用, 這應該可以找到其他相關的文章或是參考官網 https://ope.me/
目前OG會影響到的, 大概就是被分享到社群的文章/網頁, Facebook跟Twitter都支援OG來產生分享到Timeline上的預覽, Twitter則是另外支援它自己的Twitter Card, 而這其中 og:image 會影響到分享後的版面
首先, 這邊先介紹一下工具, 如果要先預覽Facebook分享出去的結果可以使用Facebook提供的 分享偵錯工具, Twitter部分則可使用Card validator
先來看看沒設定og:image的版面是怎樣一個狀況?

前面一個是分享到Facebook上的版面, 後一個則是在Twitter上會看到的, 很明顯的版面偏小, 不起眼, 分享出去後應該也引不起使用者點擊的慾望
這邊Twitter跟Facebook不太一樣的地方是, Facebook決定大小版面是以og:image的大小來決定的, 大版面的圖片需要有1200x630的解析度, 但對Twitter來說, 你如果設定Twitter card的型別是 “summary_large_image” , 那就會選擇使用大版面來顯示, 因此如果圖不是很大的話, 會像下個範例:


這邊Twitter card使用的是 “summary_large_image” , 因此可以看到結果(第二張), 版面是較大的版面, 但圖片的部分就糊的有點慘了, 而且, 重點被截到了, Facebook圖雖沒那麼糊, 但版面依然很小
現在應該很多網站都有注意使用了大圖來做為og:image了, 效果就像是這樣:

這樣版面是大得很明顯了, 但似乎有點問題, 這邊用的是LOGO, 但它賣的是"【JOYOUNG 九陽】LINE FRIENDS系列真空悶燒罐 熊大", 沒商品圖片, 我不知道大家是怎看, 至少, 不吸引我
再來看另一個例子:

看的到商品, 但部分字被遮住了, 而且"限時優惠"這個是有時效性的, 被分享出去的圖片是不會被改變的
那我自己之前的blog文章呢? 我最早設定的邏輯是這樣的, 如果文章內有圖, 就挑第一張圖, 把它放大到1200x630的規格, 如果沒有圖, 就拿標題做一張圖(前面提到的小工具)

我的文章大多偏技術面的文章, 這裡面有些是用到了流程圖, 看起來沒啥太大問題, 有些就沒那麼優了, 再來看看文章內沒有圖的狀況

自從用了這版本後, 覺得好像這樣會比較清楚一點, 與其去選一張跟內容沒那麼相關, 品質又沒保證的, 還不如使用標題來的直觀一點
但之前的小工具, 需要綁在git pre-commit, 我換台電腦就又得設定一次, 也是有點不方便, 重新來寫一個版本, 跑在heroku上, 反正文章沒那麼多, Facebook又不會常常跑來抓, Free dyno就夠用了
下面就來把這版本:Better OG 幾個實作來做一個介紹, 原始碼都在Github上, 因為都是用現成的package來簡單達成的, 所以我沒想把code整理當成一個可以直接發行的版本, 單純當範例, 大家有用到的片段可以直接拿去使用
純文字的OG Image
想達成的效果就跟前面提到這張圖一樣
使用text2img
這一部分算最簡單的, 就是前面的文章有提到的text2img, 它的設計也就是為了產生og:image, 所以很簡單就可以應用在這邊了, 我是用我自己改過的版本:
func (bog *BetterOG) drawText(text string) (*bytes.Buffer, error) {
buf := bytes.NewBuffer(make([]byte, 0))
if decoded, err := base64.RawURLEncoding.DecodeString(text); err == nil {
text = string(decoded)
} else {
return nil, err
}
var err error
var img image.Image
if img, err = bog.drawer.Draw(text); err == nil {
if err = jpeg.Encode(buf, img, &jpeg.Options{Quality: 90}); err == nil {
return buf, nil
}
}
return nil, err
}
因為我是要直接放在URL上, 像https://og.jln.co/t/W-ethuiomF3liKnnlKhheGlvcy1tb2NrLWFkYXB0ZXLngrpheGlvc-aPkOS-m-a4rOippueUqOeahOWBh-izh-aWmQ, 所以文字部分就用base64先編碼過(必須要用RawURLEncoding)
Unit test
這邊為了測試畫出來的文字是不是正確, 所以就引入了gosseract, gosseract是tesseract-ocr的go封裝, tesseract-ocr算是很老牌的OCR了, 辨識率還不錯, 不過老實說, 這邊只是想玩玩gosseract XD
func TestDrawText(t *testing.T) {
server, err := NewServer(":8888", text2img.Params{
FontPath: "../../fonts/SourceHanSansTC-VF.ttf",
})
assert.NoError(t, err)
client := gosseract.NewClient()
defer client.Close()
buf, err := server.drawText(base64.URLEncoding.EncodeToString([]byte("For testing")))
assert.NoError(t, err)
client.SetImageFromBytes(buf.Bytes())
text, _ := client.Text()
assert.Equal(t, "For testing", text)
}
使用網頁截圖來當OG Image
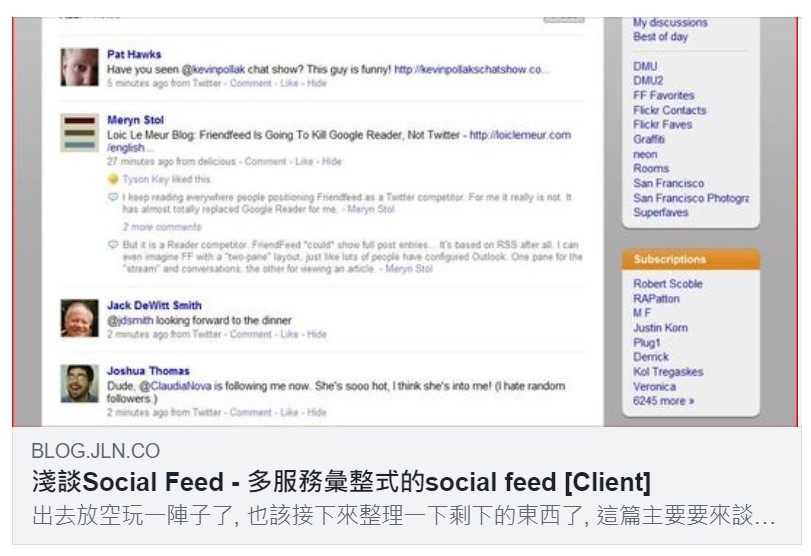
這種類型應該比較常在ptt分享文章上看到, 像這樣

這也是不錯的做法
使用chromedp來擷取網頁畫面
chromedp是透過chrome debug protocol 來操作Chrome的, 這邊就很適合從程式來操作截取網頁畫面, 只是擷取畫面, 還算蠻簡單的:
func Capture(encodedurl string) ([]byte, error) {
var err error
var decoded []byte
if decoded, err = base64.RawURLEncoding.DecodeString(encodedurl); err == nil {
url := string(decoded)
log.Printf("capture URL:%s\n", url)
ctx, _ := chromedp.NewExecAllocator(context.Background(), chromedp.NoSandbox)
ctx, cancel := chromedp.NewContext(
ctx,
// chromedp.WithDebugf(log.Printf),
)
defer cancel()
var buf []byte
if err = chromedp.Run(ctx, chromedp.Tasks{
chromedp.EmulateViewport(1200, 630),
chromedp.Navigate(url),
FullScreenshotInViewport(&buf, 90),
}); err != nil {
return nil, err
}
return buf, nil
}
return nil, err
}
這邊要擷取的URL一樣是透過base64編碼完放在url傳過來的, 因為我們要的圖大小是1200x630, 所以這邊的View port就設定成那個大小, 有一個比較要特別注意的是, 跟原本chromdp範例不同的地方是, 這邊要用ctx, _ := chromedp.NewExecAllocator(context.Background(), chromedp.NoSandbox) “NoSandbox” 的模式來初始chrome, 要不然無法在heroku下跑
這邊並不是使用chrome.FullScreenshot來擷取畫面, 取而代之的是用自己寫的FullScreenshotInViewport
func FullScreenshotInViewport(res *[]byte, quality int) chromedp.EmulateAction {
if res == nil {
panic("res cannot be nil")
}
return chromedp.ActionFunc(func(ctx context.Context) error {
format := page.CaptureScreenshotFormatJpeg
var err error
// capture screenshot
*res, err = page.CaptureScreenshot().
WithCaptureBeyondViewport(true).
WithFormat(format).
WithQuality(int64(quality)).WithClip(&page.Viewport{
X: 0,
Y: 0,
Width: 1200,
Height: 630,
Scale: 1,
}).Do(ctx)
if err != nil {
return err
}
return nil
})
}
其實這支是抄自chrome.FullScreenshot, 但不一樣的是WithClip這邊的寬高用的是1200x630, 這是因為原本chrome.FullScreenshot會抓整頁完整頁面, 要多長有多長, 結果寬度雖是1200, 但長度可能超長, 這樣的比例可能也會被Facebook視為要用小版面來顯示
佈署到heroku
chromedp是沒辦法單獨運作的, 必須要有chrome才可以正常運作, 如果要部屬到heroku, heroku的環境上是沒裝chrome的, 這該怎麼辦?
一種方式是建立自己的Build Pack, 裝個chrome跑headless mode, 不過這條路太麻煩, 不是我選擇的路
一個是在heroku上用docker image來跑, 這樣只要包裝好一個docker image就搞定了, 簡單
為了這目的, 可以選用Headless shell這個docker image當作base image, 這個image已經等同包裝好一個headless chrome了
FROM chromedp/headless-shell:latest
...
# Install dumb-init or tini
RUN apt install dumb-init
# or RUN apt install tini
...
ENTRYPOINT ["dumb-init", "--"]
# or ENTRYPOINT ["tini", "--"]
CMD ["/path/to/your/program"]
這邊的dumb-init, tini是必須的, 因為這個container不只會跑一個procewss, 包含chrome是兩個, 所以不包這個的話, 在結束container時會有zombie process造成container無法被結束
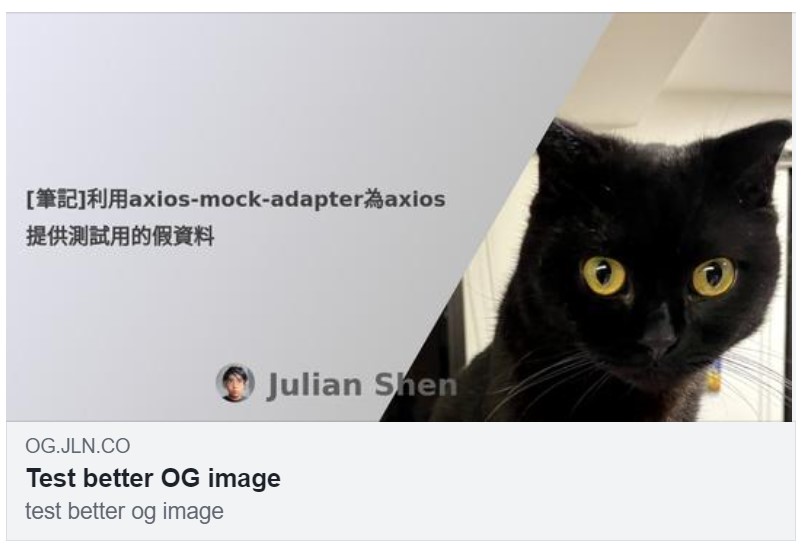
有黑貓就加分!
不過, 也不是每個網頁都像ptt那樣適合用截圖來做og:image, 後來想了一下, 我想要的大概介於兩者之間, 有文字, 但不太單調的版面, 像這樣
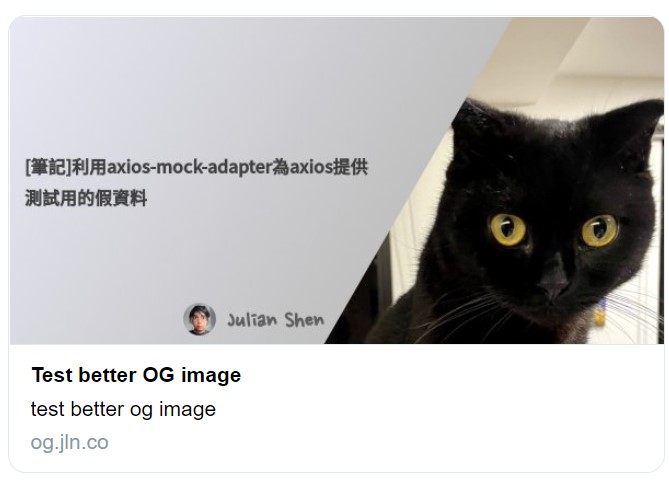
那其實這也不難, 做一個網頁範本, 用前面的截圖的方法截出來就好了, 那這也是目前最後使用的版本
小收尾
順便做了幾個小收尾
- 除了Facebook bot跟Twitter bot外, 不可以抓到產生的圖, 這是為了以防有人偷用, 用UA去判斷
- 加上cache-control, cdn-cache-control header, 前面再擋一層cloudflare
碰到的問題
目前碰到的主要問題有兩個
- heroku的free dyno冷啟動至少要6秒, 如果網頁又太慢, 那很有可能造成Facebook bot或Twitter bot timeout
- 最最詭異的部分是, Facebook部分, 字形跑掉了, 比照前面那張貓圖跟下面這張, 會發現"Julian Shen"的字形跑掉了, 前面那個是Twitter抓出來的, 後者是Facebook, 明明就同一個URL, 同一個browser render, 如果直接看那張圖字形也是正常的, 但Facebook不知道哪抓來的靈異照片