出去放空玩一陣子了, 也該接下來整理一下剩下的東西了, 這篇主要要來談一下彙整式的social feed (aggregation feeds), 這功用是什麼呢? 由於現代人擁有了很多社群網路的帳號, 但如果要一個個網站或App開著看才能看到所有的動態, 未免太累了, 因此變有這種彙整式的服務出現, 讓使用者在一個地方可以看到所有的社群動態
這種形態的應用, 有幾個有代表性的, 前一篇的概念篇裡所提到的Friendfeed, 還有就是Flipboard, 另外就是HTC的Friend stream和Blinkfeed (私心提這兩個我所參與過的)
前兩者跟後兩者的差異是在於, 前兩者在彙整social feeds是在server端, 所以client僅需要從server抓取彙整過的資料下來就好, 複雜度在於服務端並不是在client app, 而Blinkfeed跟Friendstream的差異點則是在Friendstream整合了跟社群網路相關的動態, Blinkfeed則是多了新聞的部分, 後來實作的方式為了有更多的彈性, 底層架構的部分也有所改變, 這篇會稍微提到如果是在Server端實作的一些可能做法, 但主要還是著重在client端實作的問題
做這樣一個東西, 不就是去呼叫各社群網路的API抓資料, 回來全部混在一起就好了? 如果單純只是實作一個"可以用的", 那這樣可能就可以了, 但實際上還是有些問題存在, 如
- 各家API雖類似但個家還是有很多不同
- 各家server回應時間不盡相同
- 資料時間線交錯問題
- 資料更新問題
- 網路流量問題
在看這些東西之前, 先來看看各家API的部分
Social Feed API
很多社群網站都有提供公開的API讓你去獲取使用者的Social feeds, API定義各家各有不同, 但特色都一致的, 也就是大家都是以REST API設計為主, 採資料拉取(Pull)的方式, 分頁(pagination)的方式
REST, Polling, and Pagination
因為採用了REST API的定義方式, 所以資料傳輸上大多(幾乎是全部了啦)以JSON為主, 用REST + JSON的好處是簡單, 彈性, 資料也比較適合閱讀, 不過, 別騙人了啦, 你有多少次會直接去閱讀JSON, 除非你要做啥hacking, 這連帶的也有人在實作client直接把JSON資料拿來儲存或暫存, 不過, 帶來的壞處是, 解析JSON其實並不是很經濟(後面會再稍提一下)
前面也有提到, 這樣的API設計是以"拉取"(Pull)為主, 也就是server並不會主動給你最新的資料, 而是必須你的client自行呼叫API去取得, 因此要隨時保持有最新的動態, 必須要不斷的輪詢(polling) server, 這其實也是相當不經濟的做法, 就算在熱門如Facebook, Twitter, 使用者的Social feeds不見得隨時會有最新的動態, 因此多久的輪詢間隔才是最好的, 這會是一個很頭痛的事, 太過頻繁易造成浪費, 也會造成server的負擔, 太久則會造成使用者看到的動態並不總是會是最新的, 其實少數像是Twitter, 有提供所謂的Streaming API, 這種就不是以拉取為主, 而是server會主動更新資料
一般來說, 社群網站上面"跟隨"(Follow)了越多人, 看得到的動態越多, 總不可能每次抓取資料就從頭一筆給到最新的一筆, 這樣的話, 不但花時間, 浪費流量, 也增加了server的負擔, 所以絕大部分的API, 都是從最新的往回給一定數量(比如說25則)的內容, 這樣稱之為一頁, 因此如果使用者需要往回捲回之前的資料, 就再抓取再前面一個分頁, 這樣的設計就是分頁(Pagination), 分頁的問題點在於, 社群動態的最頂頭的部分常常會再有更新的動態加入, 導致分頁會整個位移, 像下圖, 這樣會導致client有可能抓取到重複的資料, 甚至時間線錯亂
Twitter API
先來看看Twitter API的例子, 這邊就有很詳細地解釋前述的Pagination的問題, 並且講解如何用max_id和since_id來解決這一問題
Twitter在這部分經驗豐富, 他們用的解法是以"id", 有些社群網站的since會用"時間", 用時間是不好的做法, 因為就算你時間記錄到微秒, 還是很有可能有兩則以上的動態可能是相同時間的, 這樣錯亂的問題一樣存在
Twitter在抓取使用者的social feed用的API是“GET statuses/home_timeline.json”, 回傳的資料是一個Tweets的陣列如下:
[
{
"coordinates": null,
"truncated": false,
"created_at": "Tue Aug 28 21:16:23 +0000 2012",
"favorited": false,
"id_str": "240558470661799936",
"in_reply_to_user_id_str": null,
"entities": {
"urls": [
],
"hashtags": [
],
"user_mentions": [
]
},
"text": "just another test",
"contributors": null,
"id": 240558470661799936,
"retweet_count": 0,
"in_reply_to_status_id_str": null,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"source": "OAuth Dancer Reborn",
"user": {
"name": "OAuth Dancer",
"profile_sidebar_fill_color": "DDEEF6",
"profile_background_tile": true,
"profile_sidebar_border_color": "C0DEED",
"profile_image_url": "http://a0.twimg.com/profile_images/730275945/oauth-dancer_normal.jpg",
"created_at": "Wed Mar 03 19:37:35 +0000 2010",
"location": "San Francisco, CA",
"follow_request_sent": false,
"id_str": "119476949",
"is_translator": false,
"profile_link_color": "0084B4",
"entities": {
"url": {
"urls": [
{
"expanded_url": null,
"url": "http://bit.ly/oauth-dancer",
"indices": [
0,
26
],
"display_url": null
}
]
},
"description": null
},
"default_profile": false,
"url": "http://bit.ly/oauth-dancer",
"contributors_enabled": false,
"favourites_count": 7,
"utc_offset": null,
"profile_image_url_https": "https://si0.twimg.com/profile_images/730275945/oauth-dancer_normal.jpg",
"id": 119476949,
"listed_count": 1,
"profile_use_background_image": true,
"profile_text_color": "333333",
"followers_count": 28,
"lang": "en",
"protected": false,
"geo_enabled": true,
"notifications": false,
"description": "",
"profile_background_color": "C0DEED",
"verified": false,
"time_zone": null,
"profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/80151733/oauth-dance.png",
"statuses_count": 166,
"profile_background_image_url": "http://a0.twimg.com/profile_background_images/80151733/oauth-dance.png",
"default_profile_image": false,
"friends_count": 14,
"following": false,
"show_all_inline_media": false,
"screen_name": "oauth_dancer"
},
"in_reply_to_screen_name": null,
"in_reply_to_status_id": null
},
{
"coordinates": {
"coordinates": [
-122.25831,
37.871609
],
"type": "Point"
},
"truncated": false,
"created_at": "Tue Aug 28 21:08:15 +0000 2012",
"favorited": false,
"id_str": "240556426106372096",
"in_reply_to_user_id_str": null,
"entities": {
"urls": [
{
"expanded_url": "http://blogs.ischool.berkeley.edu/i290-abdt-s12/",
"url": "http://t.co/bfj7zkDJ",
"indices": [
79,
99
],
"display_url": "blogs.ischool.berkeley.edu/i290-abdt-s12/"
}
],
"hashtags": [
],
"user_mentions": [
{
"name": "Cal",
"id_str": "17445752",
"id": 17445752,
"indices": [
60,
64
],
"screen_name": "Cal"
},
{
"name": "Othman Laraki",
"id_str": "20495814",
"id": 20495814,
"indices": [
70,
77
],
"screen_name": "othman"
}
]
},
"text": "lecturing at the \"analyzing big data with twitter\" class at @cal with @othman http://t.co/bfj7zkDJ",
"contributors": null,
"id": 240556426106372096,
"retweet_count": 3,
"in_reply_to_status_id_str": null,
"geo": {
"coordinates": [
37.871609,
-122.25831
],
"type": "Point"
},
"retweeted": false,
"possibly_sensitive": false,
"in_reply_to_user_id": null,
"place": {
"name": "Berkeley",
"country_code": "US",
"country": "United States",
"attributes": {
},
"url": "http://api.twitter.com/1/geo/id/5ef5b7f391e30aff.json",
"id": "5ef5b7f391e30aff",
"bounding_box": {
"coordinates": [
[
[
-122.367781,
37.835727
],
[
-122.234185,
37.835727
],
[
-122.234185,
37.905824
],
[
-122.367781,
37.905824
]
]
],
"type": "Polygon"
},
"full_name": "Berkeley, CA",
"place_type": "city"
},
"source": "Safari on iOS",
"user": {
"name": "Raffi Krikorian",
"profile_sidebar_fill_color": "DDEEF6",
"profile_background_tile": false,
"profile_sidebar_border_color": "C0DEED",
"profile_image_url": "http://a0.twimg.com/profile_images/1270234259/raffi-headshot-casual_normal.png",
"created_at": "Sun Aug 19 14:24:06 +0000 2007",
"location": "San Francisco, California",
"follow_request_sent": false,
"id_str": "8285392",
"is_translator": false,
"profile_link_color": "0084B4",
"entities": {
"url": {
"urls": [
{
"expanded_url": "http://about.me/raffi.krikorian",
"url": "http://t.co/eNmnM6q",
"indices": [
0,
19
],
"display_url": "about.me/raffi.krikorian"
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": true,
"url": "http://t.co/eNmnM6q",
"contributors_enabled": false,
"favourites_count": 724,
"utc_offset": -28800,
"profile_image_url_https": "https://si0.twimg.com/profile_images/1270234259/raffi-headshot-casual_normal.png",
"id": 8285392,
"listed_count": 619,
"profile_use_background_image": true,
"profile_text_color": "333333",
"followers_count": 18752,
"lang": "en",
"protected": false,
"geo_enabled": true,
"notifications": false,
"description": "Director of @twittereng's Platform Services. I break things.",
"profile_background_color": "C0DEED",
"verified": false,
"time_zone": "Pacific Time (US & Canada)",
"profile_background_image_url_https": "https://si0.twimg.com/images/themes/theme1/bg.png",
"statuses_count": 5007,
"profile_background_image_url": "http://a0.twimg.com/images/themes/theme1/bg.png",
"default_profile_image": false,
"friends_count": 701,
"following": true,
"show_all_inline_media": true,
"screen_name": "raffi"
},
"in_reply_to_screen_name": null,
"in_reply_to_status_id": null
},
{
"coordinates": null,
"truncated": false,
"created_at": "Tue Aug 28 19:59:34 +0000 2012",
"favorited": false,
"id_str": "240539141056638977",
"in_reply_to_user_id_str": null,
"entities": {
"urls": [
],
"hashtags": [
],
"user_mentions": [
]
},
"text": "You'd be right more often if you thought you were wrong.",
"contributors": null,
"id": 240539141056638977,
"retweet_count": 1,
"in_reply_to_status_id_str": null,
"geo": null,
"retweeted": false,
"in_reply_to_user_id": null,
"place": null,
"source": "web",
"user": {
"name": "Taylor Singletary",
"profile_sidebar_fill_color": "FBFBFB",
"profile_background_tile": true,
"profile_sidebar_border_color": "000000",
"profile_image_url": "http://a0.twimg.com/profile_images/2546730059/f6a8zq58mg1hn0ha8vie_normal.jpeg",
"created_at": "Wed Mar 07 22:23:19 +0000 2007",
"location": "San Francisco, CA",
"follow_request_sent": false,
"id_str": "819797",
"is_translator": false,
"profile_link_color": "c71818",
"entities": {
"url": {
"urls": [
{
"expanded_url": "http://www.rebelmouse.com/episod/",
"url": "http://t.co/Lxw7upbN",
"indices": [
0,
20
],
"display_url": "rebelmouse.com/episod/"
}
]
},
"description": {
"urls": [
]
}
},
"default_profile": false,
"url": "http://t.co/Lxw7upbN",
"contributors_enabled": false,
"favourites_count": 15990,
"utc_offset": -28800,
"profile_image_url_https": "https://si0.twimg.com/profile_images/2546730059/f6a8zq58mg1hn0ha8vie_normal.jpeg",
"id": 819797,
"listed_count": 340,
"profile_use_background_image": true,
"profile_text_color": "D20909",
"followers_count": 7126,
"lang": "en",
"protected": false,
"geo_enabled": true,
"notifications": false,
"description": "Reality Technician, Twitter API team, synthesizer enthusiast; a most excellent adventure in timelines. I know it's hard to believe in something you can't see.",
"profile_background_color": "000000",
"verified": false,
"time_zone": "Pacific Time (US & Canada)",
"profile_background_image_url_https": "https://si0.twimg.com/profile_background_images/643655842/hzfv12wini4q60zzrthg.png",
"statuses_count": 18076,
"profile_background_image_url": "http://a0.twimg.com/profile_background_images/643655842/hzfv12wini4q60zzrthg.png",
"default_profile_image": false,
"friends_count": 5444,
"following": true,
"show_all_inline_media": true,
"screen_name": "episod"
},
"in_reply_to_screen_name": null,
"in_reply_to_status_id": null
}
]
眼花撩亂了吧? 這邊先不細部探討每個部分的意義, 你只需要先知道, 這雖然看來很複雜, 但有一大半你做client時"並用不上!!!" 通常只會需要內文, 連結, 回文數量, 喜愛數量, 使用者基本資料(大概就ID, 名字, 圖像就已經差不多了)
Facebook API
Facebook有相當多的功能, 因此相較於Twitter, 他的API自然複雜很多, 這邊要看的還是只有User Feed這部分, 不過似乎Facebook Graph API已經不再允許存取home timeline了, User Feed其實只能存取自己po的文
在處理Pagination上, Facebook API並不是很一致, 從這篇來看, 有幾種分頁的形式:
- 游標型分頁
- 時間型分頁
- 位移型分頁
並不是所有的API節點都支援這三種分頁型態, 例如"/user/albums"用的是游標型, 但User Feed用的是時間型, 時間型的缺點就是有可能會發生有相同時間的動態的問題, 但不管是哪一個類型 在Paging的資訊都會有一個previuos跟next的連結(如下), 因此不用太擔心要根據不同型態去組出URL這部分
//游標型分頁
{
"data":[
],
"paging":{
"cursors":{
"after":"MTAxNTExOTQ1MjAwNzI5NDE=",
"before":"NDMyNzQyODI3OTQw"
},
"previous":"https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw"
"next":"https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
//時間型分頁
{
"data":[
{
"message": "真專業,還有空橋耶",
"created_time": "2016-10-30T11:41:36+0000",
"id": "1129283437_10210116929056272"
},
{
"message": "兄弟藍瘦香菇了",
"created_time": "2016-10-29T12:45:58+0000",
"id": "1129283437_10210105741976602"
},
{
"message": "又被拖著跑了",
"created_time": "2016-10-29T06:39:29+0000",
"id": "1129283437_10210103402598119"
}
],
"paging":{
"previous":"https://graph.facebook.com/me/feed?limit=25&since=1364849754",
"next":"https://graph.facebook.com/me/feed?limit=25&until=1364587774"
}
}
在資料內容方面, Facebook回應的資料比起Twitter反而就相當的精簡, 這是有助於減低回應時間的(response time)
時間線回朔問題
剛提到Pagination時有講到在Client的設計上, 在使用者往回滑完一頁時必須要再獲取上一頁的資料, 這在單一資料源的時候問題不大, 但對彙整式的social feed, 尤其完全在Client端實作的, 會有這樣一個問題
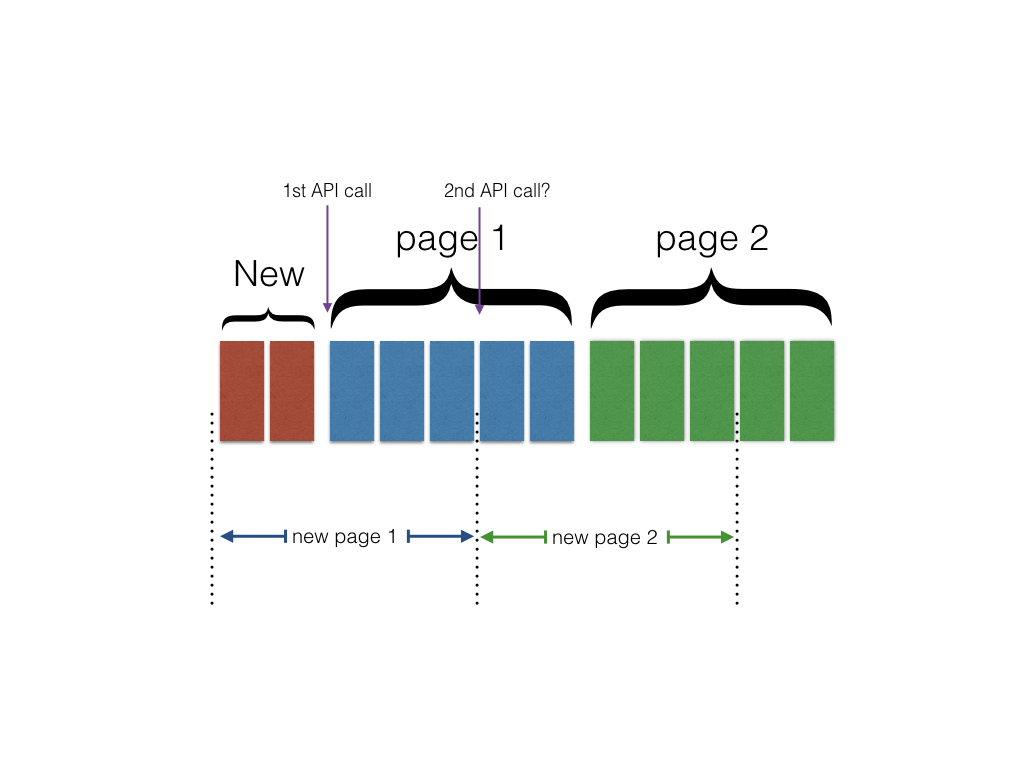
先來看看下圖:
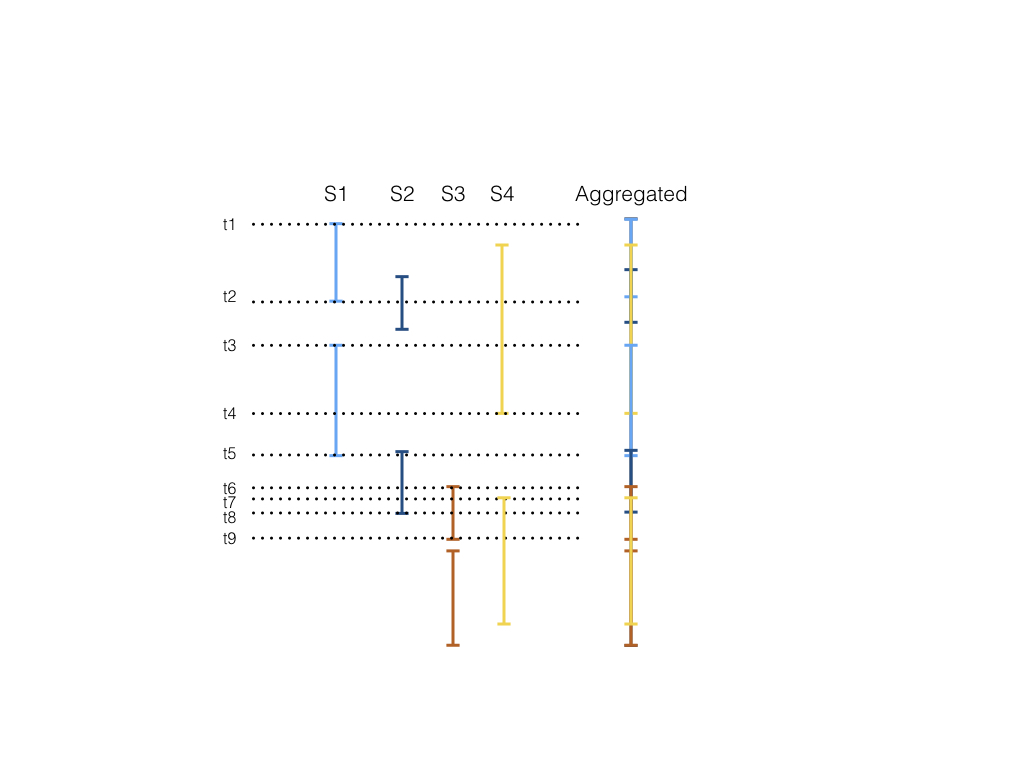
假設我們有S1, S2, S3, S4四個服務的動態要整合, 垂直每個線段是每次API call抓取到的資料的時間段(每個分頁的匙間段)
如果我們先不考慮S2-S4, 而是只有一個S1, 第一次載入的分頁內容的時間點在t1-t2間, 所以照理來說當使用者滑到快t2時, 要再發出一個新的API call抓取下一個分頁, 也就是t3-t5這段, 但如果把S2-S4列入考慮後, 會發現, 當第一次從四個服務那邊取得資料, 資料涵括的時間是從t1-t9, 如果什麼都不做處理而是照前面的邏輯來看, 必須要使用者滑到快t9時, 才會第二次抓取資料, 但由於第一次抓取時, S1缺了t2-t9間的資料, S2缺了t3之後的, S4的資料也只到t4, 因此第二次抓取資料時, 會造成這三者的資料往前回填, 這在UI顯示上會是一個比較大的災難
因此, 以這圖來說, 第一次抓取完畢後, UI上只能顯示t1-t2間的資料, 使用者滑到t2時, 就必須觸發第二次資料的抓取, 但以這例子來說, 其實第二次是不需要包含S3 的, 因為它第一次抓取的資料時間還在t5之後, 所以這邊如果能夠做省略, 而不是每次抓取資料都包含了S1-S4, 那可以省卻不少回應時間
資料格式的一致化(Data normalization)
剛剛看了Twitter, Facebook兩個API, 它的資料格式雖然都是JSON, 但內容差異很大, 但實際上來說, 以上次那篇的一張圖來做解釋:
從這張圖可以發現, 我們需要的資料並不多, 即使各家型態有所不同(例如Twitter重文字, Instagram是以圖為主), 我們還是可以歸納出我們UI所需要顯示的型態有哪些類別, 因此我們需要的也只是顯示UI所需要的部分而已, 所以我們可以把這些不同來源的資料格式一致化成同一種我們所需要的資料格式
那為何需要先一致化呢? 每次API抓回來的資料解析完直接顯示到UI上不就好了? 一般這樣的App的UI設計上, 會讓使用者一直捲頁, 因此你還是會需要把舊資料先暫存, 不管是在記憶體或是在資料庫內, 這樣使用者回捲再多也不需要再從server抓取舊資料, 但你如果把原本資料原封不動的拿來存, 像Twitter那個就會存了很多不必要的資料, 如果更偷懶直接存JSON, 那就會是效率問題了, 解析JSON過程中其實會產生不少垃圾, 效率也不高, 可能會影響UI的效能, 因此如果能夠在一開始把解析完的資料序列化到資料庫內, 會是比較理想, 因為你只需要從資料庫取相對應解析完的資料就好, 不用再一次解析JSON
背景更新
偷偷在背景更新動態是一種解決時間線回朔這個問題的方法, 因為所有資料都預先抓回資料庫, 所以也不需要煩惱什麼時後該去抓下一個分頁, 每個服務都可以獨立抓取, 丟到本地的資料庫彙整就好 ,在使用者使用程式時, 也不需要解析太多JSON, 但這帶來一個缺點是因為在背景抓資料, 會有浪費頻寬的問題, 假設使用者一天最多只看了50則動態, 但一天其實會產生一百則, 那就會有50則的資訊量是浪費了, 再加上Social API都是用輪詢(polling)的方式, 並不是會時時有資料, 所以常常很多API calls其實是不需要也浪費的
那Friendfeed的做法?
Facebook的前CTO, 也是Friendfeed創辦人之一的Brett Taylor在這篇 How do sites such as FriendFeed and Flipboard scale out their social data-aggregators? 的回答可窺知一二
在server端的做法就像背景更新差不多, 定期用crawler發api去抓取各服務的資料, 然後塞到資料庫內, 因此就沒有時間線回朔的問題了, 但問題就在於抓取的間隔, 因此在server端實作的難題就是該怎樣去取這間隔, 在OSCON 2008有一篇Beyond REST? Building Data Services with XMPP PubSub有提到:
on july 21st, 2008, they friendfeed crawled flickr 2.9 million times. to get the latest photos of 45,754 users of which 6,721 of that 45,754 visited Flickr in that 24 hour period, and could have *potentially* uploaded a photo.
- Beyond REST? Building data services with XMPP PubSub (Evan Henshaw-Plath, ENTP.com, Kellan Elliott-McCrea, Flickr.com)
但實際上來說, 並沒有那麼多的更新, 也不需要那麼頻繁的去抓取, 但這是這類型的API先天的缺陷, 也不是Friendfeed的問題, 或許在下一篇講一下怎麼設計API來改善這狀況



 (好, 我拿chacha的畫面的確是故意的 :P)
(好, 我拿chacha的畫面的確是故意的 :P)