WebRTC是一個支援瀏覽器的即時影音對話的架構, 算是一個業界標(W3C,IETF), 最近由於想做一個有影音通話的應用, 就研究了一下這東西
如果只是想嘗試一下WebRTC, 是可以直接是可以直接試AppRTC這個Google的範例, 不過這個是Web的版本, 我想要做的是 手機的版本(Android, iOS), AppRTC其實也有Android的版本可搭配
為了熟悉一下整個用WebRTC建立video call的流程, 因此我就決定改一下這個Android版本, 原本Google的版本是透過Web Socket
至於流程與架構我會建議看這影片:
如果不想看太長, 就看這個:
把Web RTC那段換成Firebase(好, 其實我蠻後悔選Firebase來實作的)其實就是把Signaling這段給換掉, 而這段流程是(節錄自影片):
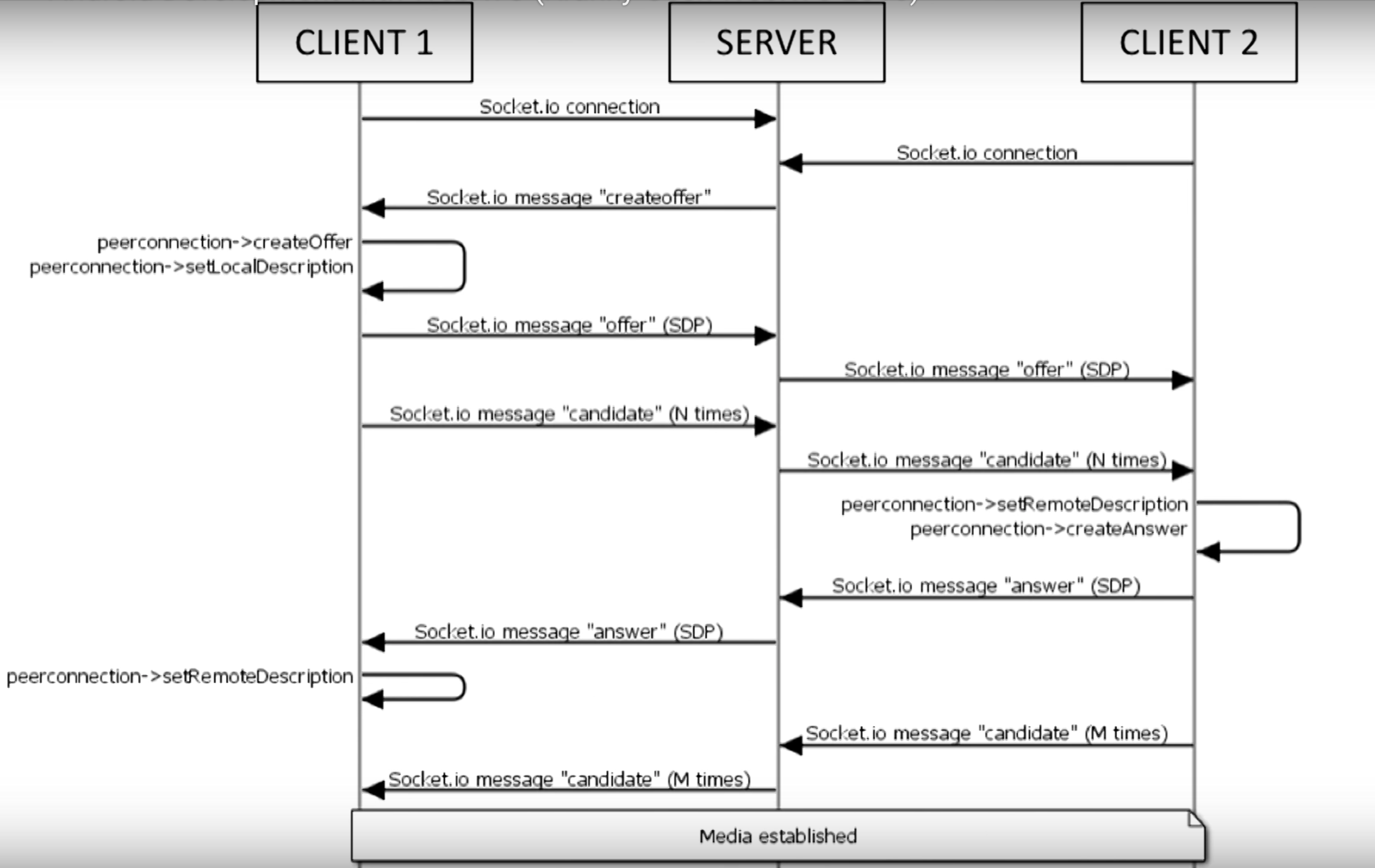
這部分其實就是交換兩邊的SDP和ICE candidate的過程, 詳細可以參考這邊:WebRTC 相關縮寫名詞簡介
結果的source code放在這邊 : apprtc-android-demo
Building WebRTC lib on Android
其實現在寫WebRTC的應用的話, 也不用從頭實作, Google老早就把它實作在Chromium裡面了, 也可以單獨build出library用
這邊有官方的如何建置出Android版本的Web RTC library, 不過, 不要照著這份文件做呀, 不然頭髮會白好幾根, 可能還build不太起來, 找了一堆網路上人家的建議也都是不要直接build, 直接用人家build好現成的, 不過, 現成的雖然有一些, 但大多是過時的, API跟現今的也不太一樣, 如果 要套用到現在的Android版本AppRTC的source code內, 大多都沒辦法用
所幸找到這個build script: pristineio/webrtc-build-scripts, 這個從下載最新的source code到build出library一律包辦, 用法也很簡單, 只要執行下面的:
source android/build.sh
install_dependencies
get_webrtc
build_apprtc
簡單明暸, 但…有幾個問題, 第一個是只能在Linux下build, 因此在Mac跟Windows下要透過Vagrant這類的工具, 而且對硬體需求也很高, 我的2012年中版的Macbook Pro retina實在是跑不動, 後來跑去Digital Ocean租了台VM來build, 本以為最便宜的可以勝任, 後來發現, 至少要4G RAM, 硬碟要20G以上的instance(哭哭, 浪費好多時間)
build出來後, 所需要的東西包含了libjingle_peerconnection.jar和libjingle_peerconnection_so.so, 把這幾個備份起來就是了, 待會build apk需要用
AppRTC 範例的Android source codes
Android的範例的source codes可以在這邊下載
不過這並不是Android studio的project格式, 因此需要用匯入的方式, 或是可以直接fork我的版本去改, 由於原本的版本使用了Web socket做singaling的管道, 因此需要Autobahn, 但你切記絕對不能用Autobahn官方最新的jar檔, 而是要用Google放在third_party裡面那個autobanh.jar(啊, 我到現在才發現名字有些許不同), 這邊的差異是, 原本Autobahn是沒有支援SSL的websocket的, 但AppRTC的websocket則是要透過SSL來連接
把jar跟so檔放到對應的目錄去後, 記得改一下app目錄下的build.gradle加入 (因為import產生的不會幫你加):
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
}
加上firebase
除了原本的Webcoket和Direct connect兩種方式外, 為了跑一次他的流程我多加了Firebase的部分, 利用它的realtime database來做Signaling這部分, 至於怎樣開始開發firebase, 就參考一下他的官方文件吧
Signaling的實作
CallActivity
選擇哪種signaling的方式是在CallActivity裡面依據roomId來看使用哪一個signaling client, 程式碼如下:
// Create connection client. Use DirectRTCClient if room name is an IP otherwise use the
// standard WebSocketRTCClient.
if("firebase".equals(roomId)) {
Log.d(TAG, "firebase");
appRtcClient = new FirebaseRTCClient(this);
} else if (loopback || !DirectRTCClient.IP_PATTERN.matcher(roomId).matches()) {
appRtcClient = new WebSocketRTCClient(this);
} else {
Log.i(TAG, "Using DirectRTCClient because room name looks like an IP.");
appRtcClient = new DirectRTCClient(this);
}
原本有WebSocketRTCClient和DirectRTCClient, 如果是IP的話就用DirectRTCClient,這邊我多加一個FirebaseRTCClient, 只要roomId是firebase就會使用這個(我偷懶)
FirebaseRTCClient
XXXRTCClient這部分實作了signaling的部分, 因此我參考了WebSocketRTCClient和DirectRTCClient的內容來寫FirebaseRTCClient
跟WebSocketRTCClinet一樣, 它必須實作AppRTCClient, AppRTCClient這個Interface定義如下:
/**
* AppRTCClient is the interface representing an AppRTC client.
*/
public interface AppRTCClient {
/**
* Struct holding the connection parameters of an AppRTC room.
*/
class RoomConnectionParameters {
public final String roomUrl;
public final String roomId;
public final boolean loopback;
public RoomConnectionParameters(String roomUrl, String roomId, boolean loopback) {
this.roomUrl = roomUrl;
this.roomId = roomId;
this.loopback = loopback;
}
}
/**
* Asynchronously connect to an AppRTC room URL using supplied connection
* parameters. Once connection is established onConnectedToRoom()
* callback with room parameters is invoked.
*/
void connectToRoom(RoomConnectionParameters connectionParameters);
/**
* Send offer SDP to the other participant.
*/
void sendOfferSdp(final SessionDescription sdp);
/**
* Send answer SDP to the other participant.
*/
void sendAnswerSdp(final SessionDescription sdp);
/**
* Send Ice candidate to the other participant.
*/
void sendLocalIceCandidate(final IceCandidate candidate);
/**
* Send removed ICE candidates to the other participant.
*/
void sendLocalIceCandidateRemovals(final IceCandidate[] candidates);
/**
* Disconnect from room.
*/
void disconnectFromRoom();
/**
* Struct holding the signaling parameters of an AppRTC room.
*/
class SignalingParameters {
public final List<PeerConnection.IceServer> iceServers;
public final boolean initiator;
public final String clientId;
public final String wssUrl;
public final String wssPostUrl;
public final SessionDescription offerSdp;
public final List<IceCandidate> iceCandidates;
public SignalingParameters(List<PeerConnection.IceServer> iceServers, boolean initiator,
String clientId, String wssUrl, String wssPostUrl, SessionDescription offerSdp,
List<IceCandidate> iceCandidates) {
this.iceServers = iceServers;
this.initiator = initiator;
this.clientId = clientId;
this.wssUrl = wssUrl;
this.wssPostUrl = wssPostUrl;
this.offerSdp = offerSdp;
this.iceCandidates = iceCandidates;
}
}
/**
* Callback interface for messages delivered on signaling channel.
*
* <p>Methods are guaranteed to be invoked on the UI thread of |activity|.
*/
interface SignalingEvents {
/**
* Callback fired once the room's signaling parameters
* SignalingParameters are extracted.
*/
void onConnectedToRoom(final SignalingParameters params);
/**
* Callback fired once remote SDP is received.
*/
void onRemoteDescription(final SessionDescription sdp);
/**
* Callback fired once remote Ice candidate is received.
*/
void onRemoteIceCandidate(final IceCandidate candidate);
/**
* Callback fired once remote Ice candidate removals are received.
*/
void onRemoteIceCandidatesRemoved(final IceCandidate[] candidates);
/**
* Callback fired once channel is closed.
*/
void onChannelClose();
/**
* Callback fired once channel error happened.
*/
void onChannelError(final String description);
}
}
主要就是定義了如何處理connect, disconnect, 還有怎麼去註冊SDP和ICE candidate, 在確定好連接成功後, AppRTCClient要負責呼叫onConnectedToRoom來通知 CallActivity已經可以準備建立video call的後續流程, 且要負責處理如果Signal server(這邊是firebase)有傳來遠端的SDP跟ICE candidate, 要負責呼叫SignalingEvents對應的處理 (這邊一樣會叫到CallActivity, 而CallActivity則會使用PeerConnectionClient來處理需要傳遞給PeerConnection相關的參數)
這邊用Firebase處理Signaling的方式是監聽某一個key的改變, 有新的裝置連接, 註冊SDP, ICE Candidate, 就寫到這下面去, 這其實不是一個很好的方式, 因為這下面只要有值的改變, 就會觸發, 不像是WebSocket那個版本是一來一往的API calls, 而且你不知道每次觸發被更動的是哪一部分, 一開始發生了好幾次PeerConnection重複註冊SDP才讓我發現因為這原因被重複呼叫的問題
TURN server
WebRTC是P2P的, 因此如果不具備穿牆能力的話, 在牆外就會被擋掉, 一開始我本來想說試驗P2P而不走TURN Server穿牆的(因為我一時也懶得架一台), 結果測試時老是連不上, 後來才發現我阿呆, 我的測試環境是一台實體手機, 另一台是電腦上跑模擬器, 本以為兩個(手機, 電腦)是同一個區網沒問題, 後來才想到模擬器是在另一個虛擬網路, 因此還是有需要TURN server
如果不想架一台, 要怎辦? 用Google免錢的, 他們做了這個demo, 一定有! 因此就偷看了一下WebRTCClient的code跟傳輸內容,發現它跟https://networktraversal.googleapis.com/v1alpha/iceconfig?key=AIzaSyAJdh2HkajseEIltlZ3SIXO02Tze9sO3NY 去要TURN server list, 所以基本上只要照copy下面這段就好:
private LinkedList<PeerConnection.IceServer> requestTurnServers(String url)
throws IOException, JSONException {
LinkedList<PeerConnection.IceServer> turnServers = new LinkedList<PeerConnection.IceServer>();
Log.d(TAG, "Request TURN from: " + url);
HttpURLConnection connection = (HttpURLConnection) new URL(url).openConnection();
connection.setDoOutput(true);
connection.setRequestProperty("REFERER", "https://appr.tc");
connection.setConnectTimeout(TURN_HTTP_TIMEOUT_MS);
connection.setReadTimeout(TURN_HTTP_TIMEOUT_MS);
int responseCode = connection.getResponseCode();
if (responseCode != 200) {
throw new IOException("Non-200 response when requesting TURN server from " + url + " : "
+ connection.getHeaderField(null));
}
InputStream responseStream = connection.getInputStream();
String response = drainStream(responseStream);
connection.disconnect();
Log.d(TAG, "TURN response: " + response);
JSONObject responseJSON = new JSONObject(response);
JSONArray iceServers = responseJSON.getJSONArray("iceServers");
for (int i = 0; i < iceServers.length(); ++i) {
JSONObject server = iceServers.getJSONObject(i);
JSONArray turnUrls = server.getJSONArray("urls");
String username = server.has("username") ? server.getString("username") : "";
String credential = server.has("credential") ? server.getString("credential") : "";
for (int j = 0; j < turnUrls.length(); j++) {
String turnUrl = turnUrls.getString(j);
turnServers.add(new PeerConnection.IceServer(turnUrl, username, credential));
}
}
return turnServers;
}
// Return the contents of an InputStream as a String.
private static String drainStream(InputStream in) {
Scanner s = new Scanner(in).useDelimiter("\\A");
return s.hasNext() ? s.next() : "";
}
把這邊拿來的list當ICE candidate, 就可以成功透過Google的TURN server去穿牆了(長久之計還是自己架一台吧)