這應該是這系列最後一篇了吧, 雖然回頭看, 可能有些漏寫, 不過, 以後想到再補吧, 如果還沒看過前兩篇, 可以再複習一下: 概念篇,多服務彙整
這篇主要要著眼在如何做Timeline這東西(怎又突然把它叫Timeline了? 好吧, 複習了一下很多文章, 發現這還是比較通用的名詞)
先借用一下以前跟老闆報告時, 老闆問的
"做這很難嗎?"
這不是啥記恨啦(雖然我還蠻有印象這問題跟我的回答的), 而是開始做這個的時候, 我也覺得應該沒什麼難的, 不過, 實作這個功能本身的確不難, 倒是要讓它可以擴展(scale)這件事, 的確會比較麻煩, 也不止一個方法做, 先從基本來看一下
什麼構成一個Timeline (Social feed)
Twitter和Facebook主要把這東西分為兩類 - User timeline和Home timeline
User timeline主要就是單一使用者的近況更新, 也就是所有的內容都是由那個使用者產生, 並以時間排序(不然怎叫Timeline), 這部分倒沒什麼困難的, 因為它就是單一個人的流水帳(從軟體的角度也可以說成他活動的"log")
Home timeline包含的則不是單一個人的, 而是包含你關注的人所有的動態, 在Twitter就是你follow的人, 而Facebook則是你的朋友加上你關注的人(follow)和粉絲頁, 講"follow"其實蠻貼切的啦, 有點偷窺(光明正大吧?), 又有點跟蹤狂的感覺, 但現今的Home timeline大多(尤其是Facebook)不是用時間排序, 好像也不能真的叫Timeline (ㄠ回來了, 這樣我叫Social feed好像比較貼切 XD)
假設我follow了user1, user2, user3等三個人, 那我的Home timeline就會變成這樣:
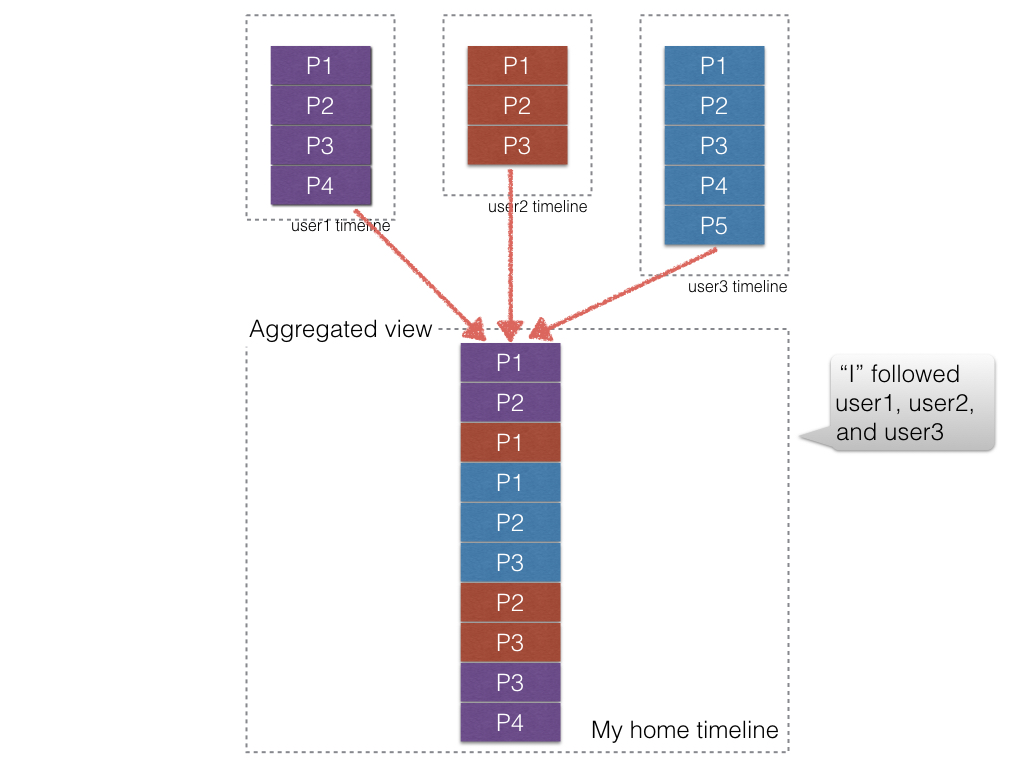
Ok, 其實這有點像前一篇講的多服務彙整那種, 不同的是, 這些feeds是來自於同一個來源, 並不是多個不同的服務, 比較沒資料異質性問題
1 9 90 理論
在切入實作面之前, 先提一下這個理論, 這邊有Mr. Jamine對這個的解釋: “網路內容的 1/9/90 定律” (他用"定律", 但定律是比較恆常的, 但這比例並不是那麼的絕對, 所以我比較覺得用理論或假設比較適合)
這理論說的是, 大約有90%(甚或以上)的人是屬於讀者, 9%的人會參與進一步互動(比如說按讚或回文), 只有1%的創作者(你可以看一下你自己是屬於哪類的人), 根據我的經驗, 讀者可能會多於90%, 創作者甚至可能少於1%
那對於開發者來說, 知道這些有什麼用? 我個人是覺得一個開發者或是架構設計者, 必須要清楚暸解所做的東西所會產生的行為才能產出一個好的架構, 以這個來說, 如果要設計一個高度可擴展的架構的話, 我們可知道, 絕大部分的request其實都是讀取(read), 高併發(highly concurrent)的寫入機會並不大(反而比較容易發生在like, comment)
比較直覺的實作方式
好, 難免的, 我一開始也是選用這種方式 - 都交給資料庫(database), 這邊的資料庫, 不管SQL或No-SQL, 差不多原理啦, 雖然說針對Feed這種time squences看起來像比較適合No SQL, 但Facebook不也是用My SQL(雖然用的方式比較是key-value的方式)
依照前面的說法, 我們可以簡單的假設有兩種資料 - 使用者(User)和內容(Feed)
- 使用者可以跟隨(Follow)其他使用者(這邊引用Twitter的設定), 因此每個使用者會有n個"follower"
- 使用者可以發文(Feed/Post), 每則發文都有(只有)一個作者(author)
- 每個使用者的Homeline是由他跟隨的所有人的發文所組成
- 每次client來要求homeline最多給m則(比如說25則)
按照這樣的說法, 我們可以想像Query或許長得像這樣(No SQL版本自行想像):
SELECT * FROM FEED WHERE AUTHOR IN (SELECT FOLLOWERS FROM USER WHERE ID='myid') ORDER BY TIME LIMITS m
這邊暫時先省略掉query出來你還要再query出user大頭照跟人名的部分, 但加上這部分每次至少要有兩次queries
這樣不就搞定了? 有什麼問題? 有, 後面就會撐不住了! (切身之痛), 先來看看什麼問題
查詢效率
從上面的query來說, 它還包含了個sub query去取出所有的followers, 所以這整串在資料庫裡可能的做法是, 把所有相關使用者的feed取出, 在記憶體中排序, 取前m個, 前面有提到, Feed就像流水帳, 全部的人加起來可能不少, 這聽起來就像是耗時耗CPU的查詢
因此在兩個狀況下就慘了:
- 讀取高併發時
- 使用者follow了"一大堆"人!!!
關於第一點, 這很容易發生呀! 90%的人一天到晚窺探…ㄟ …關心…人家在幹嘛, 當一堆這些queries湧入, 資料庫會非常忙碌的, 因為沒有不同的兩個人會follow同樣的人, 根本無法cache
第二點其實更慘了, follow個幾個人還好, 幾十個人還搞得定, 偏偏這個社群網路時代的, 幾百人是標配, 上千人的也不少, 如果有上萬, 可能更跑不動了(Facebook限制你只能交5000個朋友, Twitter超過5000也是選擇性的讓你少量follow, 所以上萬目前應該還比較少見)
Materialized View
有些資料庫, 像是MySQL, Postgresql, Cassandra (3.0+)都有支援Materialized view, materialized view就像是一個query的snapshot, join的部分是發生在create或是refresh時, 因此用來解決讀取高併發可能是可行的, 因為讀取時只有單純的query, 直到有更新時再呼叫refresh
但對於更新比較頻繁, 比較熱門的social network service, 資料庫的負擔還是不算小
Sharding
如果以時間為基準來做sharding, 或許可以解決這兩個問題, 因為不是所有的人不時都在更新狀態, 所以在含有最新的shard裡面包含的可能只有少數人的feed, 這減少了遍訪所有人的feed的工, 而且不用排序所有的feed
但還是有幾個問題:
- 無法join, 如果根據feed的時間去做sharding, feed跟user就不見得在同一資料庫, 這樣就無法join了
- 邊界問題, 有可能你需要的資料剛好就在時間間界的附近, 導致一開始query不到足夠的資料
其實上面問題寫程式解決都不是問題啦, 這邊想說的只是, 沒辦法以一兩個簡單的queries就搞定了
大家都怎麼做
這邊講的"大家"就那些大咖囉, Facebook, Twitter, Pinterest, Tumblr …等等, 關於這個問題, 其實Yahoo曾經出過一篇論文:
“Feeding Frenzy: Selectively Materializing Users’ Event Feeds”
如果沒耐心看完論文(我也沒耐心), 這邊先簡單提一下兩種模式:
- Push model
- Pull model
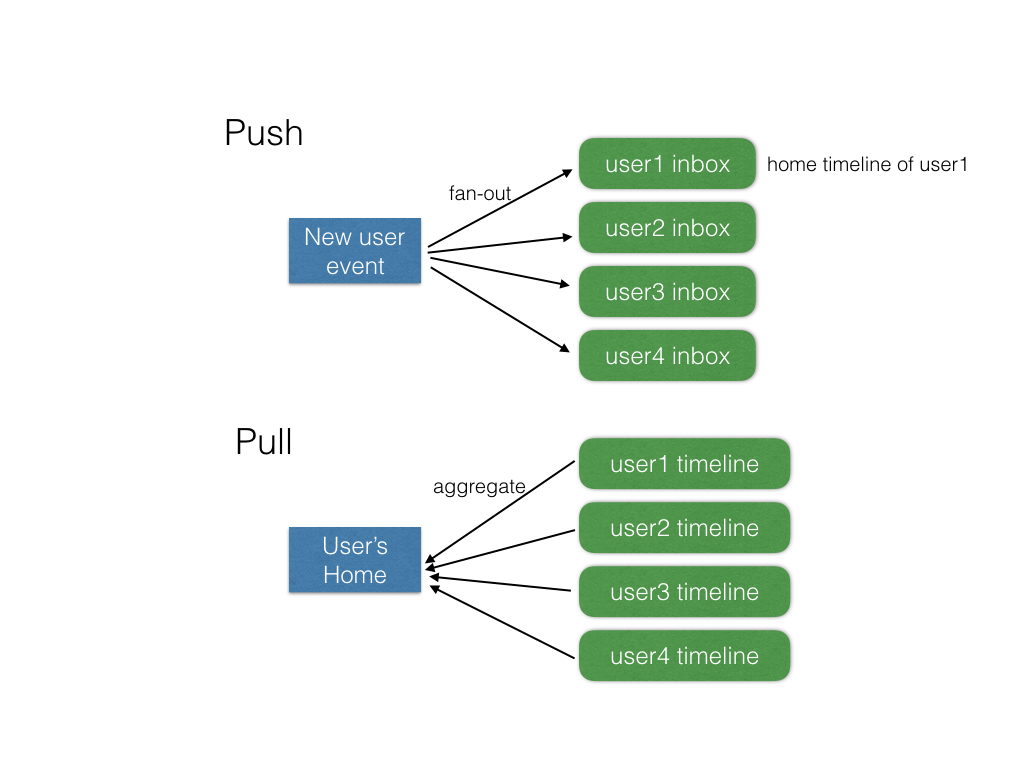
Push model又被稱為Megafeed(根據某場Facebook的分享), 而Pull model則是Facebook使用的Multifeed, 其實不管哪種模式, 大多不是直接存取資料庫增加資料庫的負擔, 而是大量的應用快取(cache), 像是Memcached, Redis等等
簡單的來說, Push model在整合feed的時間發生在寫入, 而Pull model則是發生在讀取
Push model (Megafeed)
這是Twitter所採用的方式, 也是我以前採用過的做法, 我自己則是把它稱為Inbox model, 比較詳細的內容推薦可以參考Twiter的:
先來看看他們這張架構圖
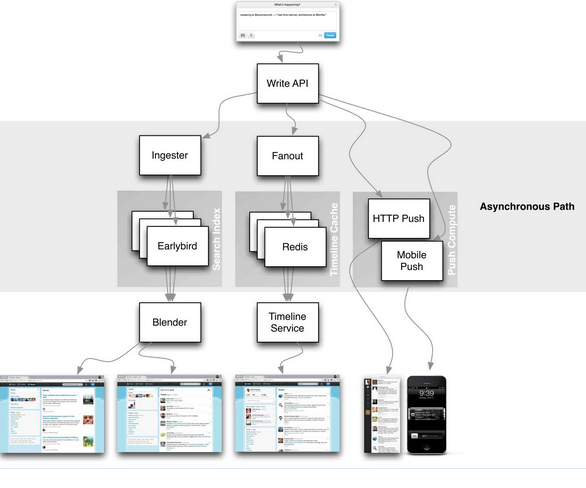
Home timeline的部分主要是中間的那個流程, 這做法比較像是E-mail一樣(所以我才稱它為inbox), 當使用者發表了一則新的動態後, 系統會根據有訂閱這則動態有那些人(也就是follow這個使用者的人), 然後把這則動態複製到各個訂閱者的Home timeline (Inbox)上
這方法的優點是, 對於讀取相當之快, 因為Home timeline已經在寫入期間就準備好了, 所以當使用者要讀取時, 不需要複雜的join就能取得, 在做pagination也相當簡單, 因為本來就是依時序排下去的
但缺點是, 很顯而易見的, 非常耗費空間, 因為每個timeline都要複製一份, 假設你被上千人follow, 就要上千份, 因此Twitter只有存ID和flag, 詳細的內容跟Meta data, 是後來才從cache去合併來的, 另外Twitter也只存了最近的八百則, 所以你不可能得無窮無盡的往前滑
另一點就是耗時, 這種寫入通常是非同步的, 使用者發布動態後, 他只知道他動態發布成功了, 但系統還需要在背後寫到各個Inbox中, 因此他不會知道別人其實可能還看不到的, 對於一個follower數量不多的不是問題, 但如果像是Lady gaga那種大人物, 有幾百萬粉絲, 那就是大問題了! 寫入幾百萬的timeline即使只寫入memcached也是相當耗時的事, 而且這會產生時間錯亂的問題, follower比較少得很快就做完了, 所以很容易看到比較熱門的人物的貼文比較晚出現
Twitter是把follower多的人另案處理, 也就是讀取時段再合併(那就是類似下面要講的multifeed了), 這樣可以省下一些空間跟時間, 另一種可行的做法(我們之前的做法), 就是不寫到所有人的timeline, 而是只cache最近有上線的人的timeline, 這樣就算Lady gaga有幾百萬粉絲, 實際上最近才有上線的可能才幾十萬或更少, 處理這部分就好了, 如果cache裡面並沒有現在上線這個人的timeline, 就在從資料庫讀取合成就好
不過總歸來說, 這方法讀取快, 但寫入慢, 耗費空間, 較適合讀比寫多上許多的應用
此外其實也有不同的變形, 像是Pinterest:
Pull model (Multifeed)
Facebook採用了一個完全不同的方式, 叫做Multifeed, 這方式從2009開始在Infoq就一直被提到:
- Facebook: Science and the Social Graph 2009, by Aditya Agarwal
- Scale at Facebook 2010, by Aditya Agarwal
- Facebook News Feed: Social Data at Scale 2012, by Serkan Piantino (Aditya Agarwal這時候應該跑到Dropbox去了)
這跟Push model有什麼不同? 其實說起來跟前面一開始用DB的方式比較像, 就是在讀取時, 才取得所跟隨的人的feed, 合併並排序, 但這樣不是讀取很沒效率嗎?先來看看圖:
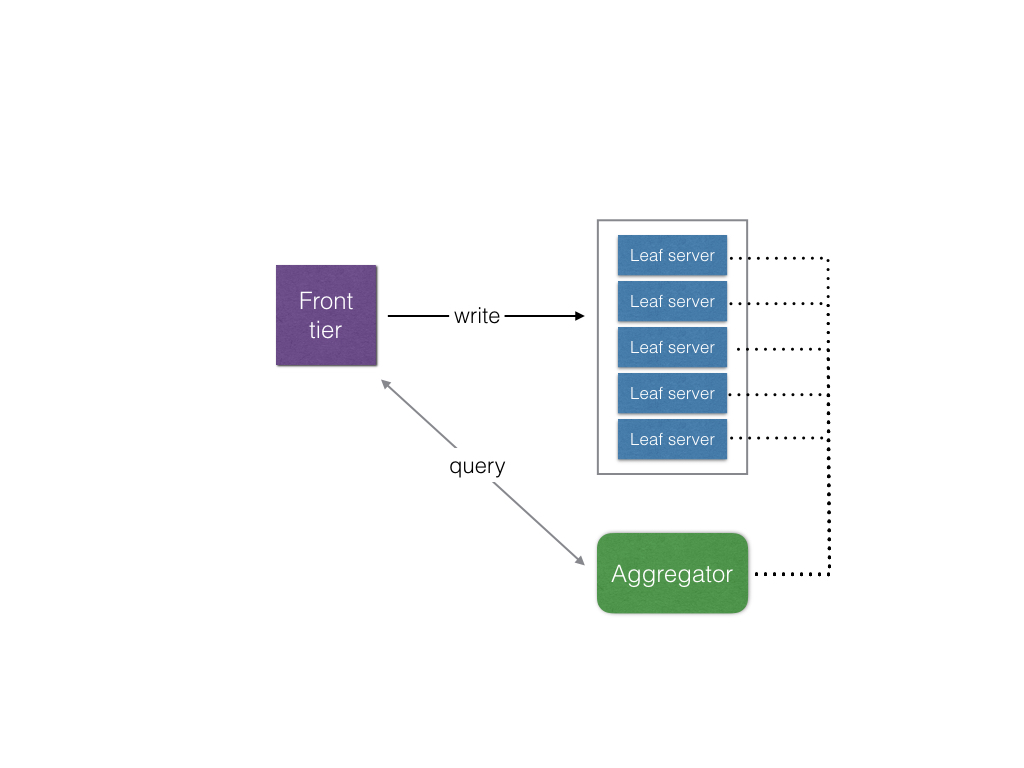
- 在寫入時, feed資料只會寫入"一個"leaf server, 應該是根據user去分流的
- leaf server主要是memcached, 所以都是in memory的
- 在memory裡面不可能保存所有動態, 只會保存最近一段時間的 (所以不可能包含所有人所有的動態, 在做整合時就輕鬆多了)
- 前端跟Aggregator query後, Aggregator會去跟"所有"的leaf server問所有相關的人的feed再回來整合
因為資料存儲跟處理都在memory, 所以可以很快, 但還是要考慮到網路的部分, 因此leaf server跨區的話效率就不會高了, 自然空間需求會比Pull model來得少, 但home timeline的讀取時間就較長了(因為是read time aggregation的關係),也不會有名人問題, 不會因為follower多, 複製耗時耗空間 另一個優點是, 排序的方式控制在Aggregator, 因此很容易立刻更動規則, 不像pull model, 當home timeline組好後要去變動它就較麻煩
混搭風
當然沒有絕對的好壞, 兩種模式各有優缺, 所以也有人採用的是混合模式, 根據使用者使用頻率來決定, 這就跟穿衣服一樣, 每個人怎搭衣服都是不一樣的, 端看你要怎混搭
REST API的問題
在前面一篇多服務彙整裡有提到REST API都是輪詢(polling)的模式, 不管資料有沒更新, Client都是會常常來server查詢資料, 這對server可能會是夢靨, 因為只有1%在努力創作, 所以搞不好有很大量的查詢都是浪費的, 而這些查詢通常是造成系統多餘負擔的元兇
關於這問題, 我有兩個想法, 不過都還沒實際去實證過
- 增加HEAD的API, 大部分REST API是以GET直接抓取資料, 所以針對個別資源(Resource), 應可實作HEAD, 讓Client在實際去查詢資料前先確訂一下資源的更新時間, 資源的更新時間在資料更新時就可以放在cache內了, 相對的可以省傳輸的數據量跟處理時間
- 利用PUSH, 現在大部分的應用都在手機上, 也大多有實作PUSH, 當有資料更新且App在前景時, 利用PUSH通知有資料更新, Client收到後才會真的去抓取, 不過這比較起來感覺相對負擔較重
另外這篇也是值得去參考(只是這個還要帶入XMPP):