VIDEO
為什麼用這開場? 跟要講的內容有啥關係? 其實…沒有….只是剛剛看完Continental第一集, 又覺得基哥講這句很帥!!!
“What do you need?”
“Small and smaller”
容器化技術玩多了後, 可能會有人跟你說, 容器的映像檔越小越好, 小到一個極致是最完美的, 所以曾經(現在還有嗎?)有一度, 以alpine基底的映像檔很流行, 但到底要小到多小才夠? 而且建置這個, 就有點像調酒一樣, 放入了基酒(Base image)後, 你還會在上面一層層往上疊加東西, 而且你要加的東西, OS的套件管理又會幫你加一大堆依賴套件(Dependencies), 當你疊了一堆有的沒的之後, 就算你基酒再純粹, 出來的東西還是會很混濁(很肥)
所以, 大小是有關係的嗎? 大部分的人知道要"小", 但不是每個人都想過, 為何要小? 要把它做的小小的, 不外乎幾個原因:
傳輸成本: 尤其現在大多流行用Kubernetes管理容器, 當節點(node)失效時, 容器常常需要在節點中搬移, 大的映像需要更多的傳輸頻寬跟時間讓節點從container registry下載下來, 以致於會需要花更多的時間來重建容器, 拉長系統回復的時間 安全性: 一個映像中裝越多不同的套件, 碰上套件的安全漏洞機率越高, 另外如果安裝了shell就給了人可以去執行一些程式的機會(甚至很多映像其實是以root權限在執行), 如果裡面又有了package manager, 就又可以進去任意安裝軟體, 甚至如果裡面包了一些敏感的設定檔, 資料, server certificate, 那就更增加敏感資料給別人拿走的機率 可維護性: 這跟2是有關的, 當你套件越多, 碰到安全漏洞需要patch的頻率越高, 尤其如果是base image, 很多應用程式的映像都仰賴於你, 當你更新時, 他們勢必也要一起更新到最新版本 所以我的看法是, 要追求的應該不是"minimal", 而是"optimal", 只包入自己所需要的就好, 不需要的東西通通塞進去不是一件好事
那, 我們需要的是怎樣的image? 需要怎樣的base image? 我覺得這要拆兩部份來看 – Build 和Runtime , 大部分的程式語言, 在建置(Build)時, 需要的東西總是比之後執行的時候來得多, 像java在單元測試時需要一些額外的jar檔, 這些在執行階段是不需要的(也不需要javac), nodejs也是有一些dev only的套件在執行時期是不需要的, go在建置後,那個單一執行檔也就夠了, 很多東西都不需要跟著一起被包入container image之中, 但大部分的人其實不太知道要用Multi-stage build , 把Build 和Runtime 給分開, 一旦分開了, runtime所需要的基底(base image)就可以使用很精簡的版本, 而build time則可以用比較完整的程式建置環境, 所以關鍵點會在於 Multi-stage build 的使用
Distroless 是一組由Google所維護的base images, 旨在提供一些不包含像是shell和package manager 這類的不必要的東西的映像給執行階段(Runtime)使用, 以增進容器安全性, 它是基於debian建置而來的, 在基於debian 11和debian 12兩種基礎上, 並提供static, base, cc, java, python, nodejs相關runtime的image
那怎樣利用這一系列的image? 這是拿來當作base image來使用的, 而且就是拿來當runtime base image來使用的, 先以go當例子:
FROM golang:1.21 as build
WORKDIR /go/src/app
COPY . .
RUN go mod download
RUN go vet -v
RUN go test -v
RUN CGO_ENABLED=0 go build -o /go/bin/app
FROM gcr.io/distroless/static-debian11
COPY --from=build /go/bin/app /
CMD ["/app"]
這例子很清楚的就是一個multi-stage build, 用golang:1.21當作build image, 而用static distroless作為base image, 因為go建置出來的是一個static binary, 不需要有其他依賴, 所以用這最小的版本就足夠了
那再看看java:
FROM openjdk:11-jdk-slim-bullseye AS build-env
COPY . /app/examples
WORKDIR /app
RUN javac examples/*.java
RUN jar cfe main.jar examples.HelloJava examples/*.class
FROM gcr.io/distroless/java11-debian11
COPY --from=build-env /app /app
WORKDIR /app
CMD ["main.jar"]
他就必須要用到distroless/java11-debian了,因為這版才有java runtime (JVM), 另外, 既然是Google出品, 可以搭配Bazel用也一點不意外, 這邊可以看範例
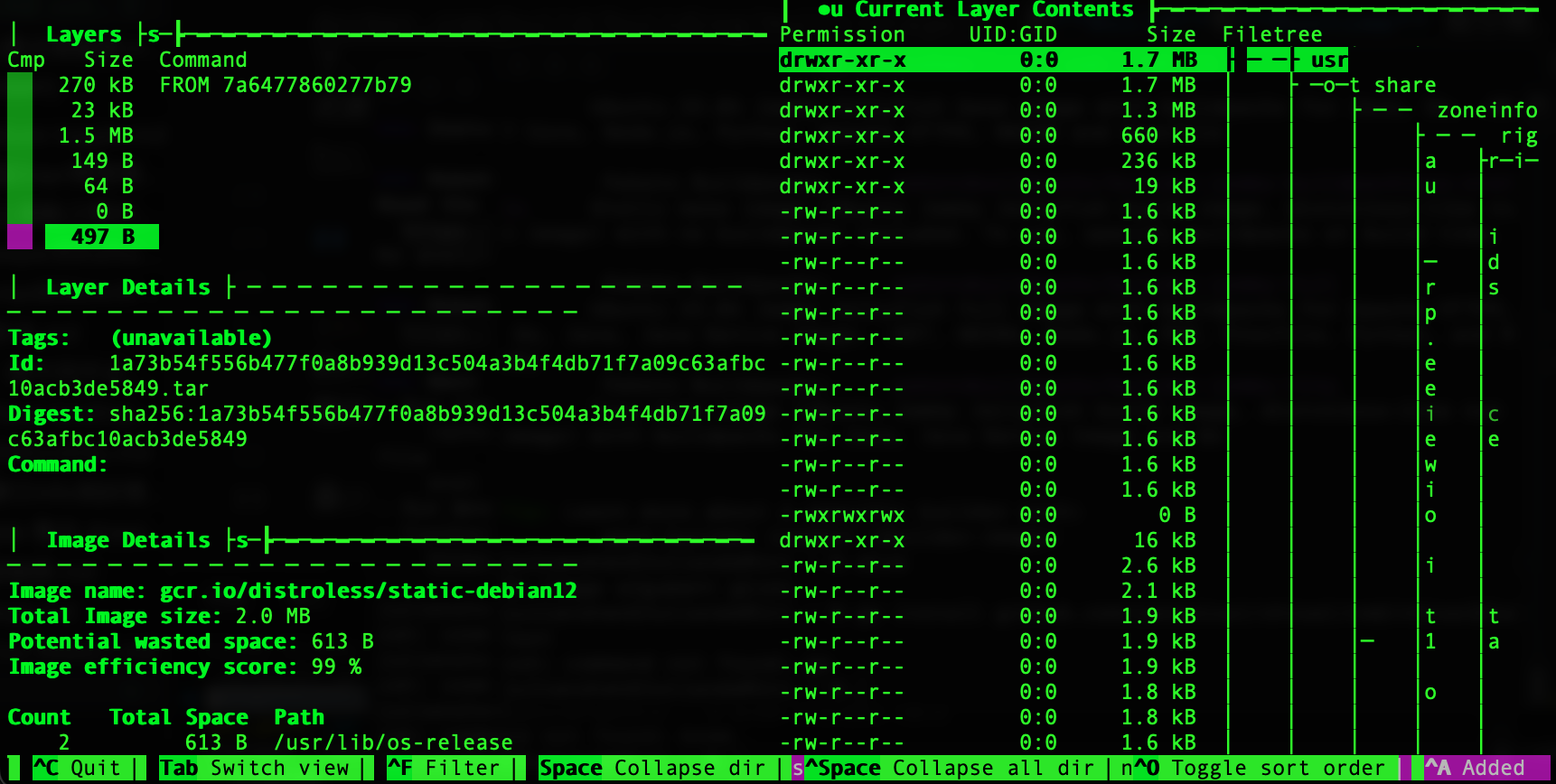
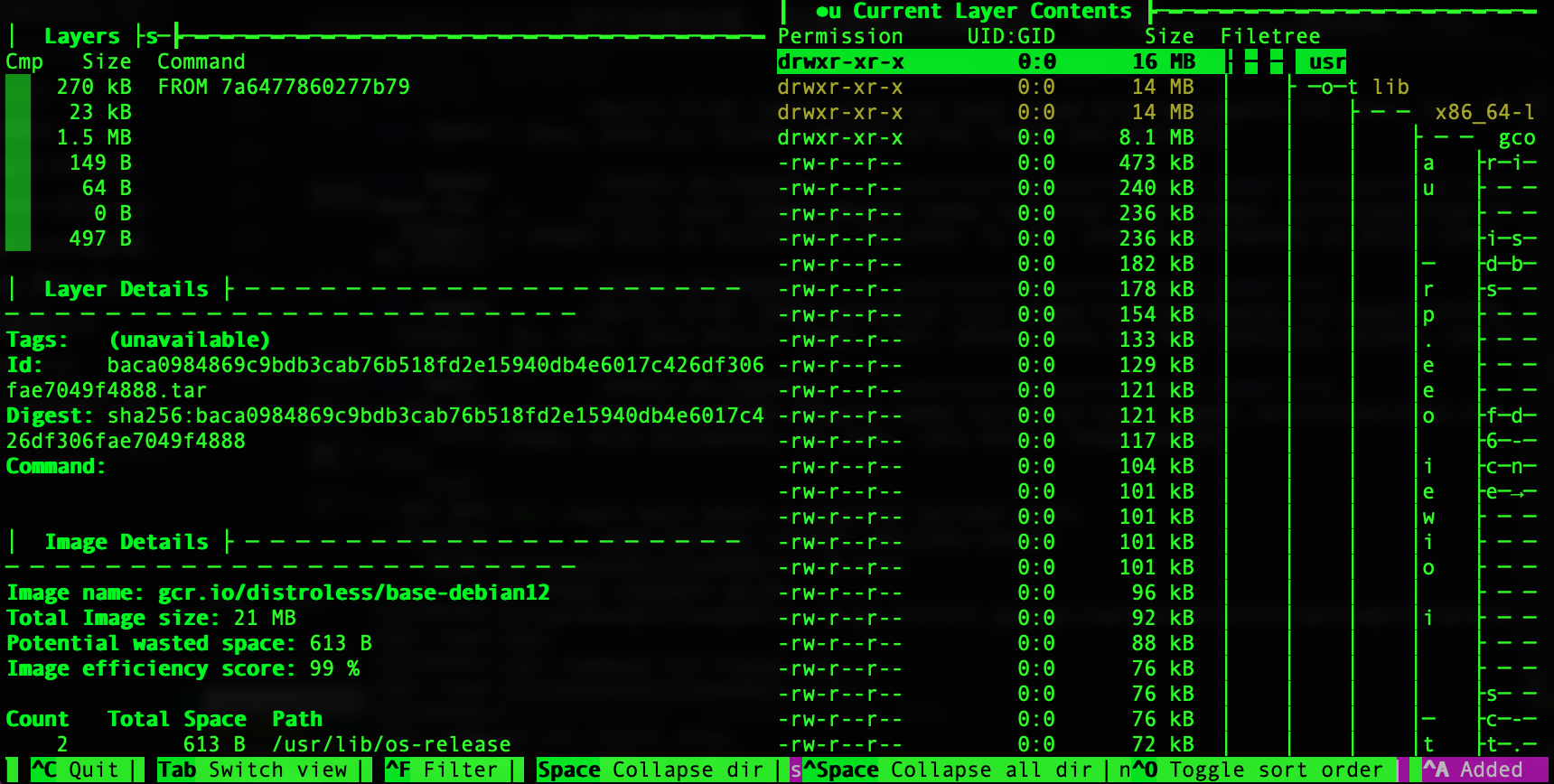
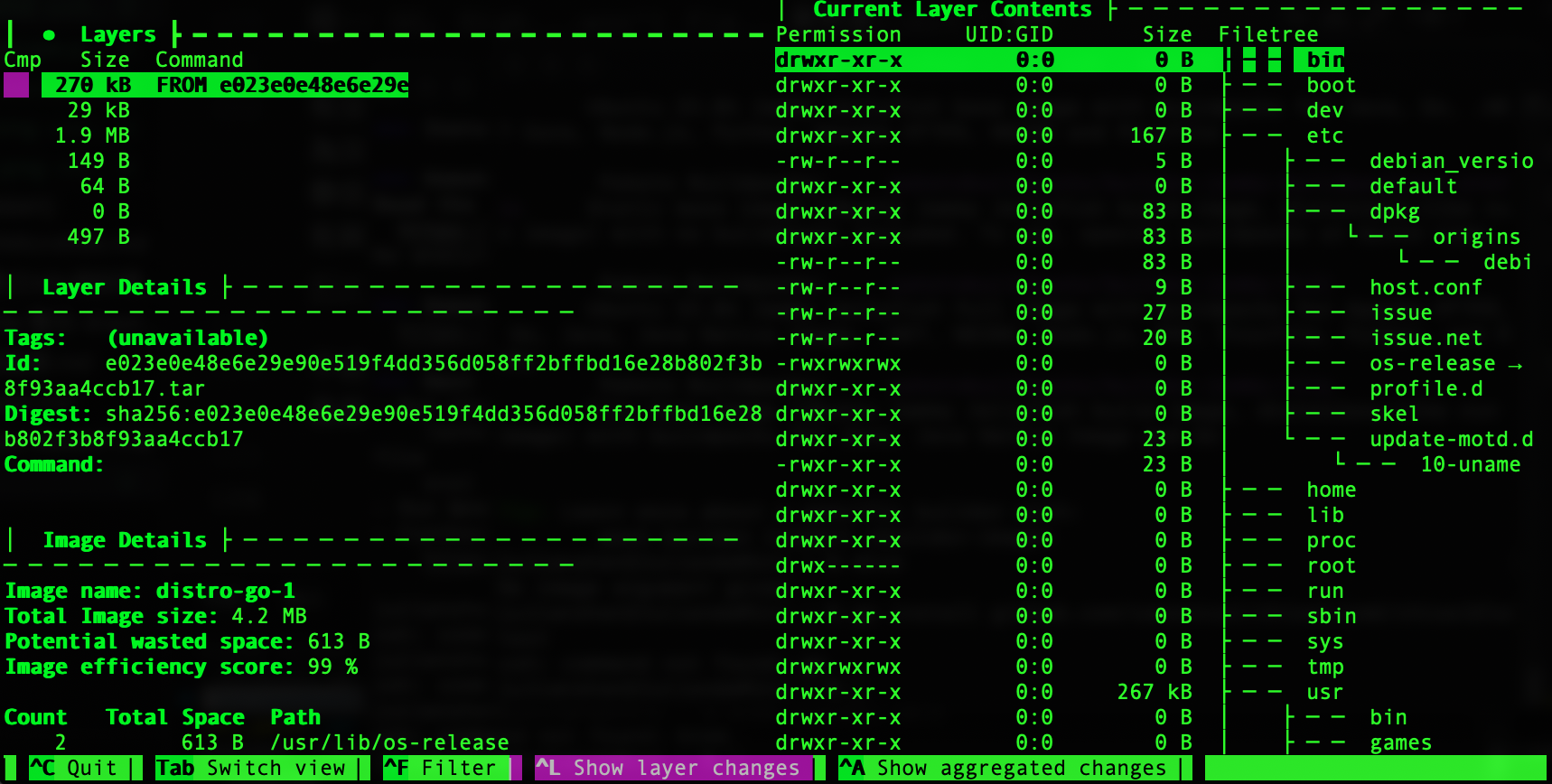
說到大小, distroless的映像最小的 gcr.io/distroless/static-debian12 只有大約2MB, 用dive 把它拆解來看, 其實裡面也沒啥東西, 光一個zoneinfo就佔掉1.7MB:
相對於alpine感覺好像的確小很多
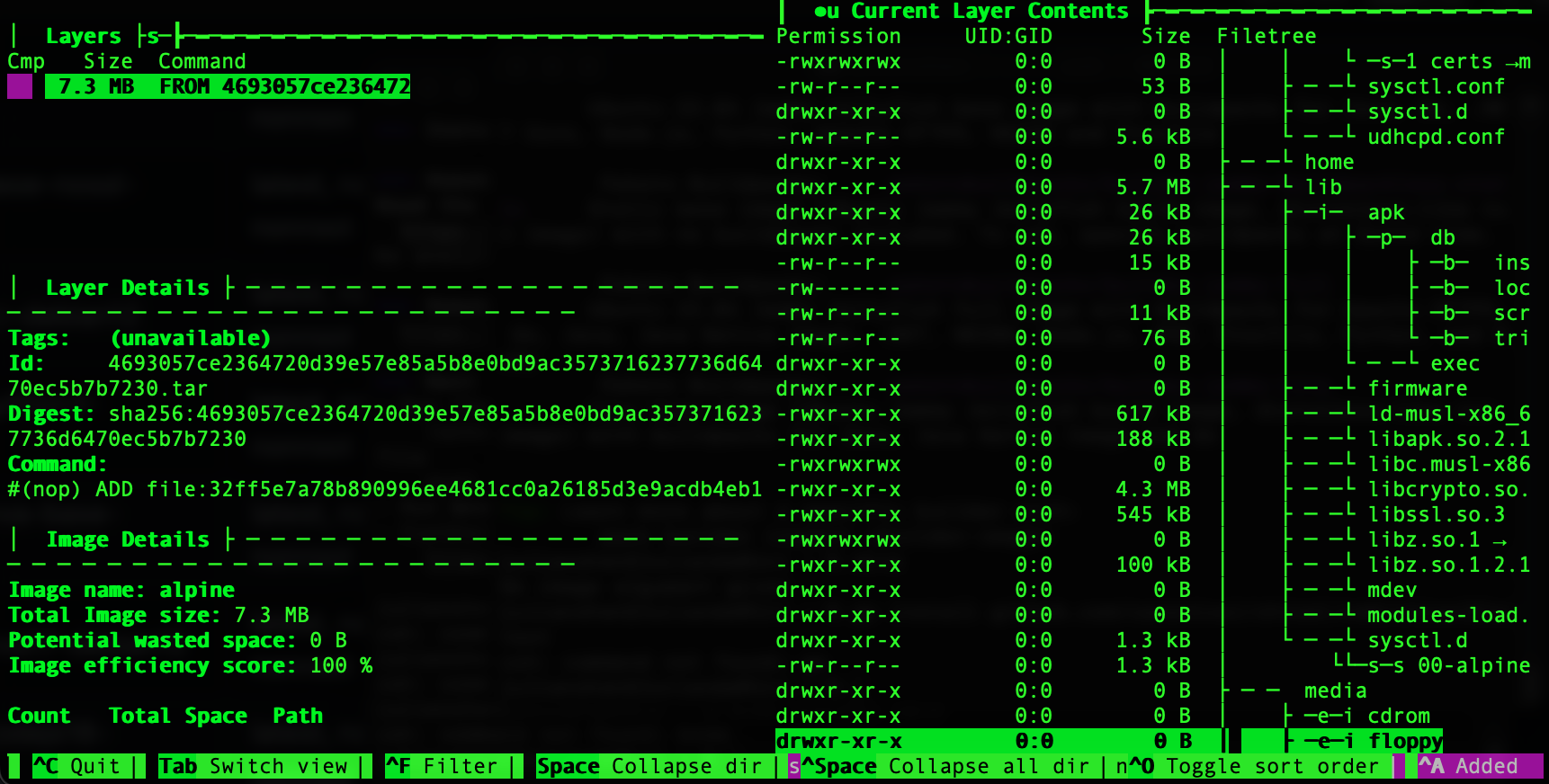
但其實仔細看一下, 這大小是有點不太公平, gcr.io/distroless/static-debian12不像 alpine內包了 busybox, apk, musl libc, 對於可以static compile的語言像是go, rust, 用static其實就夠了, 但有蠻多還是要libc的, 所以要比應該也是要用gcr.io/distroless/base-debian12 這個包入libc6的版本來比
不意外的, 光glibc就吃掉大部分了, 相較之下alpine還是比較小, 可見, 小不是它的重點, 如果要的是安全, 不包額外的套件, non-root, no shell & package manager才是這類的base image的賣點之一
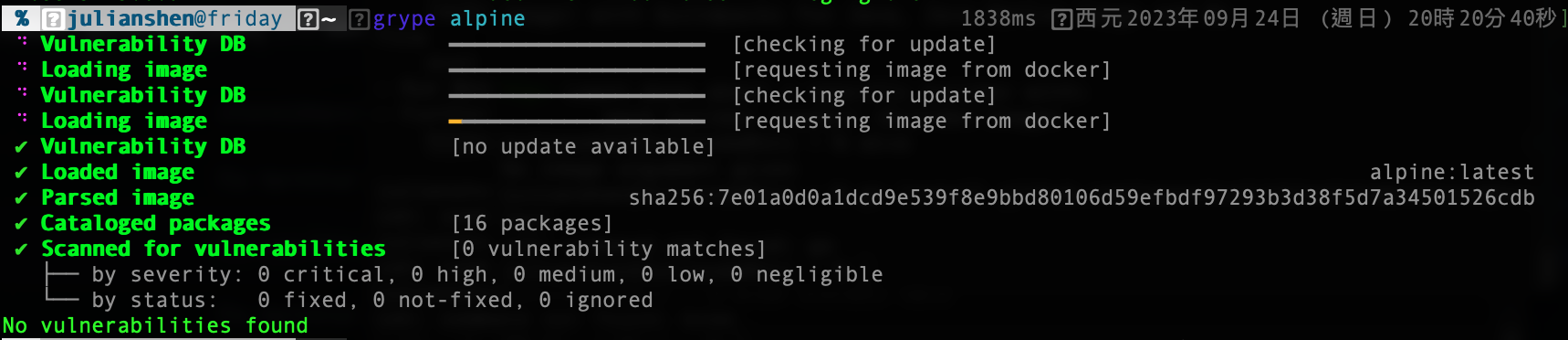
那談到安全, 我們也來跟alpine來做個相比好了, 這邊用grype 這套弱掃工具來掃描各自的最新版本(latest):
首先來個alpine的:
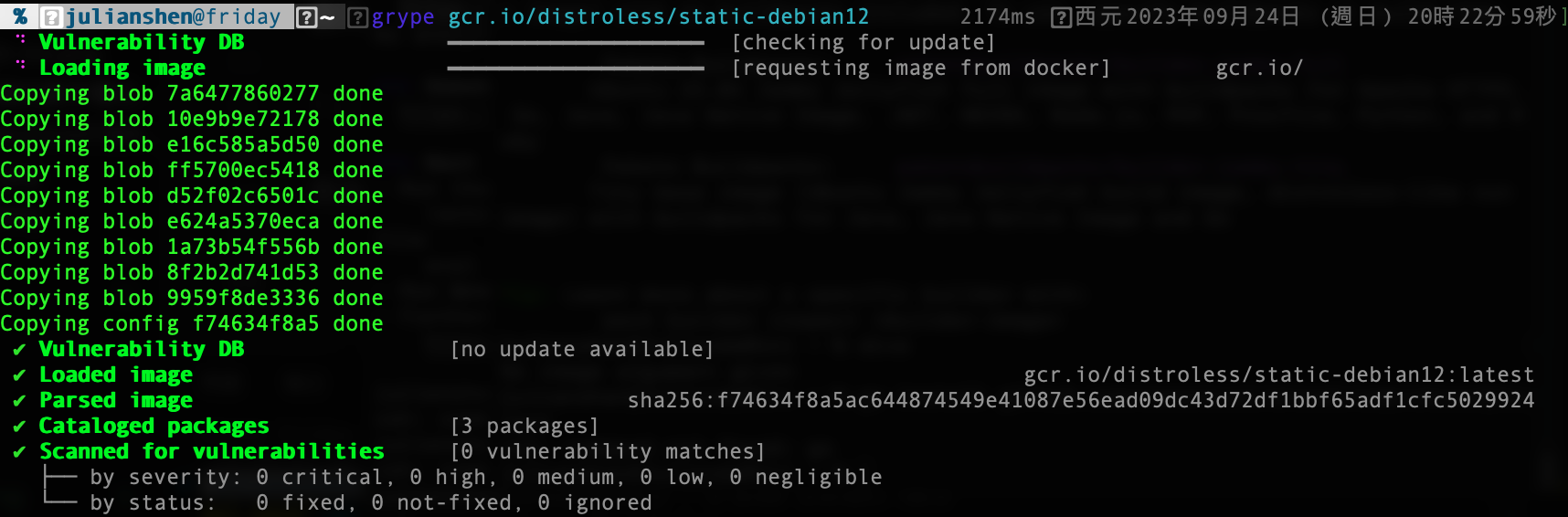
完全都沒有, 好棒棒! 至少在這最基本的版本還蠻乾淨的, 那接下來就distroless static:
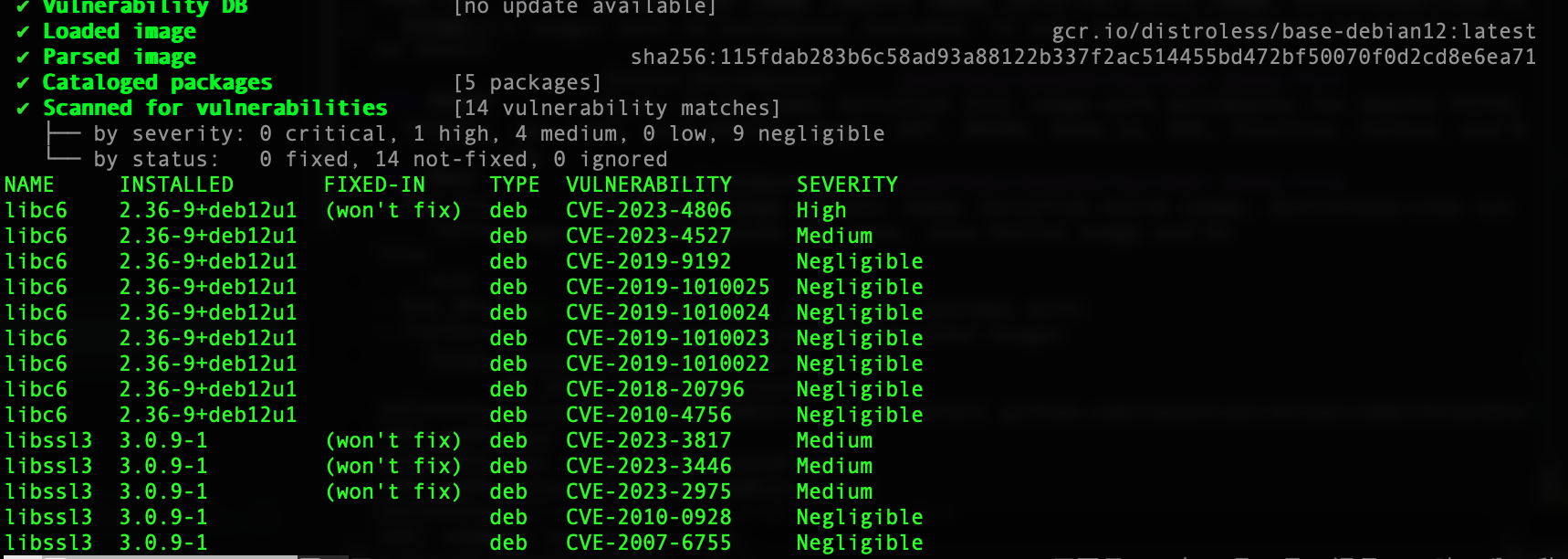
這也沒有, 不過如果真掃得出來就神奇了啦…因為這包幾乎完全沒有東西呀, 那接下來看distroless base:
哇~~ GG, High…won’t fix…果然是libc6, 那其他基於這個的就不用太看下去了, 不過, 這樣比並不見得公平, 那只是我現在掃有掃到這些, 隨時都有可能會有新的漏洞, 也會有新的修復, 真正要比可能就是更新這些漏洞修復到底多快, 可能比較實在
有沒其他的缺點? 由於基於debian, 所以只能用debian套件, 安全性更新應該就相依於debian了, 另外因為沒package manager的關係(連deb都沒喔), 除了他提供的幾個image外, 你如果想在上面加別的套件, 舉個例, 如果你用到了libffmpeg, 你要怎弄出一個image是有含有ffmpeg的? 目前應該只能透過Bazel, 有興趣的話, 可以參考JAVA image的BUILD , 不過Bazel會有點入門的門檻就是
不過其實如果是像go這種static build的, 用gcr.io/distroless/static-debian12反而應該不會是最佳的, 我們用它的範例做一個版本來分析一下:
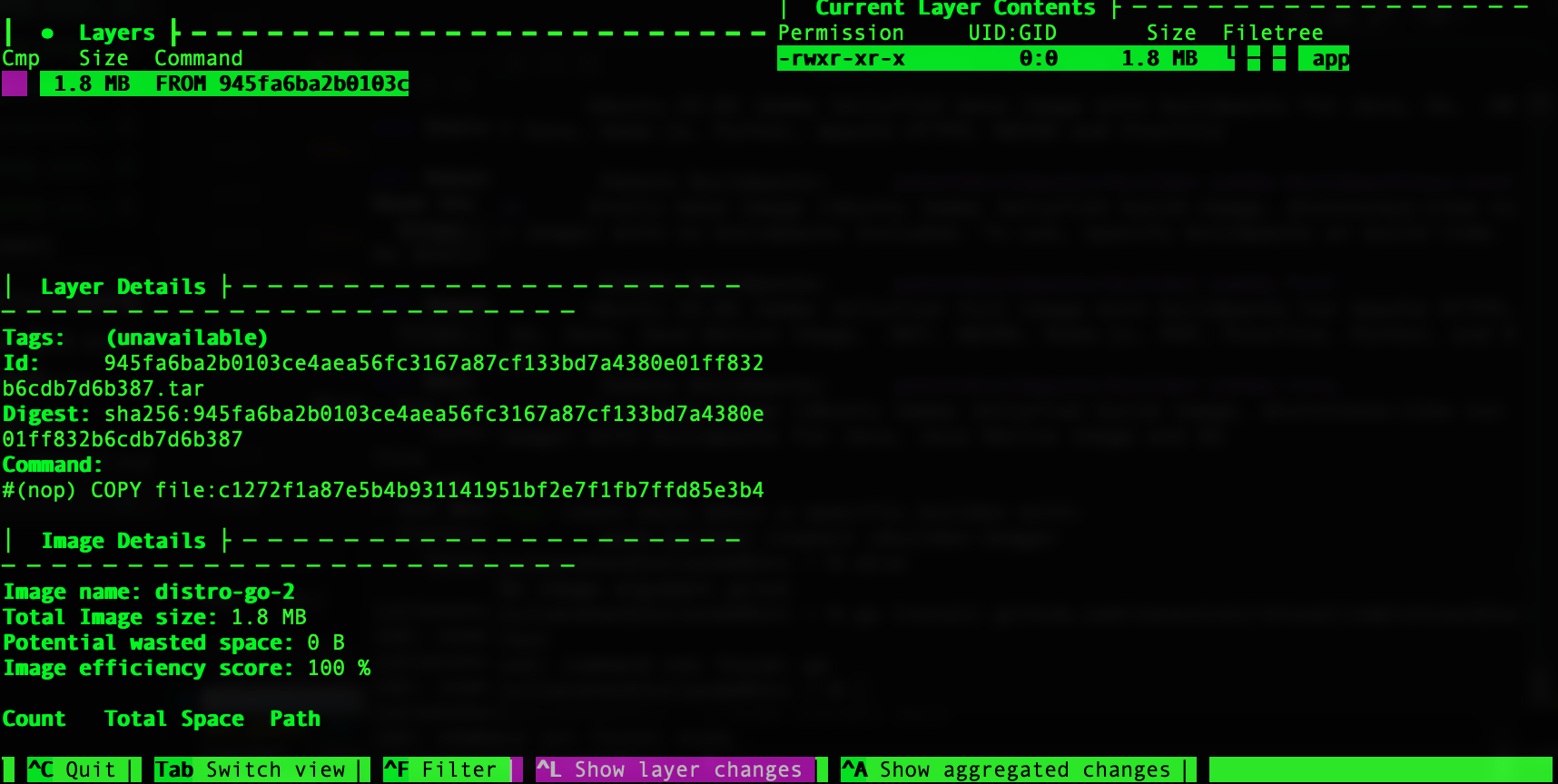
大小是4.2MB, 大概就是多加上build出來的檔案1.8MB而已, 很小, 沒多餘的東西, 其實蠻好的呀, 不過你如果把Dockerfile改成:
FROM golang:1.18 as build
WORKDIR /go/src/app
COPY . .
RUN go mod download
RUN go vet -v
RUN go test -v
RUN CGO_ENABLED=0 go build -o /go/bin/app
FROM scratch
COPY --from=build /go/bin/app /
CMD ["/app"]
再來看看結果:
怎回事?只有1.8MB, 對, 只有app本身那1.8MB, 什麼其他東西都沒有, 這應該是更簡潔的, 因為用了scratch, 就是一個完全空的映像, 這樣其實就能跑了(其實容器下就是Linux呀), 所以像是go, 應該用scratch會比distroless來得好, 不過其實這範例還少了點東西, 還是需要包入zone info跟ca, 這樣時區才不會錯, ssl連線也才可以正常, 不過這應該還不到2MB才對
UBI Micro and Buildah Google搞了個distroless, Linux發行商們怎會吞得下這口氣呢? RedHat的做法就是UBI Micro這個distroless的image
RedHat這做法有點不一樣是, 他只丟一個相當於Google的distroless base, 裡面沒套件管理員, 可以算是一種distroless, 如果要安裝套件, 則靠buildah和yum, 這點倒是有點有趣, 來個範例看看怎來建置一個java image好了:
首先我們要把ubi micro給掛載到目錄去, 所以我們要透過buildah unshare進入到root模式, buildah from的作用跟Dockerfile裡的from的作用類似, 就是我們要以某個image當做基底來建置, 這範例就是ubi micro, 然後我們透過buildah mount把這個新的image給掛載到一個目錄去
接下來就簡單了, 基本上你要放啥東西到這個image, 就只要把檔案放到那目錄下就好了, 所以就算裡面沒包裹套件管理, 那我們其實只要用 yum install --installroot $micromout 就可以把套件裝到目錄不用在裝套件管理員到image內了
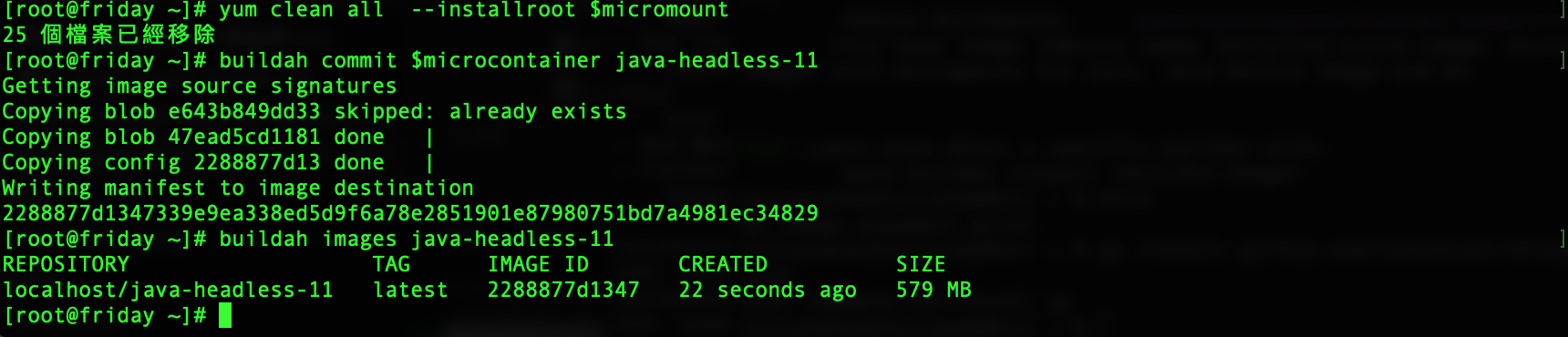
做完之後, 我們要記得 buildah umount和buildah commit $microcontainer java-headless-11, 這樣我們就可以有一個叫java-headless-11的新image
但, 怎那麼肥? 有沒搞錯, 將近600MB, 一般大部分的java image了不起也只有3xxMB, gcr.io/distroless/java17-debian12更是只有228MB, 這也就是這方法的缺點, yum會幫你管好依賴, 但其實很多東西也不用到完全, 像這個例子, 裡面光locale就有225MB, 這扣掉後也是頂多3xx MB, 去研究了一下, Google distroless的java也是沒包全部的local, 因此還是可以再瘦, 但就不在這邊討論, 因此, 的確, 使用套件管理來裝, 有些不必要的依賴可能也就混入了
不過, buildah提供了一個Dockerfile以外建置container image一個不錯的方法, 比起Google Distroless用Bazel應該會好上手很多
Ubuntu Chisel 這做法我還沒很深入去看, 可以參考: Chiselled Ubuntu: the perfect present for your containerised and cloud applications , 或是下一段影片
VIDEO
GitHub: https://github.com/canonical/chisel
原來似乎就是從package著手在取出自己要的, 結合scratch, 不過我還沒搞懂它切割縫合的做法, 這邊就先不多做解釋
其他的Distroless 像是Microsoft也有Marinara , 它是以Microsoft CBL-Mariner 2.0為基礎去製作Distroless image, 以它做出的 mcr.microsoft.com/openjdk/jdk:17-distroless, 我掃不到有啥安全漏洞, 蠻優秀的, 也只有三百多妹嘎
Buildpack 我之前也有介紹過Buildpacks , 雖然這跟這話題好像關係不大, 不過, 它其實也有一個paketobuildpacks/builder-jammy-tiny的builder可以讓你build出比較小的image, 使用方法如下
pack build myimage --builder paketobuildpacks/builder-jammy-tiny --path .
如果應用程式如果是寫好後建置成container image, 不太會需要裝額外的套件的話, 找一個適當的build image來建置程式, 然後基於一個適當的runtime來建置成image, 這樣一個簡單的multi-stage Dockerfile就可以做到了, 但用這方式的話, base image更版的話就要再去更新Dockerfile, 其實也是有點不方便, 如果把這整個封裝在buildpacks內, 應該也是不錯的做法, 這樣如果有需要更新base image的話, 用pack來rebuild應該就簡單多了, 應該找時間來研究一下怎建buildpack