之前寫了一些爬蟲, 想說來補一篇這樣的文章好了
可能是之前"所謂"的大數據(Big Data)太過流行, 以至於網路爬蟲好像是一種顯學, 隨便Google一下都可以找到一堆用python加上BeautifulSoup 相關的文章, 這可能也是因為, 現在網路上的資料, Open data的, 提供API的, 在比例上還是非常的少數, 但網頁的數量真的多到很難統計(想到早期還真是屈指可數) 要取得網頁內的內容, 解析HTML, 做字串的處理就是一個必要的基礎, 這也難怪python + BeautifulSoup 一直廣泛的被採用
不過, 當你真的去寫一個爬蟲, 突然就會發現了, 代誌不是這麼單純呀, 不是去抓個html回來解析一下就有自己想要的資料了呀, 而是會發現, 怎麼大家正正當當的網頁不寫, 一堆奇技淫巧, 繞來繞去的, 網頁廣告內容也一堆, 很多網頁都很難抓到自己想要的資料呀!!!
真的來說, 做爬蟲是一種Hacking的活動, 天下網頁萬萬種, 為了總總不同的目的, 早已不是幾個簡單的html標籤就做出來的了, 還搭配了很多程式的技巧在內, 因此要從裡面萃取資料出來, 常常還真的是要無所不用其極
那到底做爬蟲會先需要懂什麼?
- HTML
- CSS
- DOM
- DOM Selectors
- Javascript
- Regular Expression (正規表示式)
- Chrome dev tool
- Curl
以上這幾個東西可能是基本必須懂得, 而不是程式語言, 那反而其次, 很多程式語言都有很好的能力跟工具來做, 另外需要具備的是耐心, 眼力, 直覺, 和運氣
底下就拿我之前弄過的幾個東西當範例, 由於我寫比較多Go和nodejs, 所以就不用(主流的)Python來做範例了
範例一 : 文章內容分析 (如新聞, 部落格文章等等)
這應該是比較常見的應用, 單純抓取文章內容去做分析, 常碰到的麻煩是現在網站放了大大小小的(補釘)廣告, 那些跟內容不相干, 也不會是我們想拿來分析的目標
底下這個範例是從Yahoo! News的RSS抓取新聞文章連結, 再從這些連結的文章內找出關鍵字:
這段code非常的簡單, 主要也只用到以下這幾種東西:
- rss parser
- go-readability
- 結巴
簡單的來說就是先從rss內找出所有新聞的連結再一個個去爬, 然後用go-readability精簡出網頁內文, 再用結巴取出關鍵字
readability
這一個library以往的用途就是清除不必要的html tags跟內容(像是廣告), 只留下易讀的內文(純文字), 以這個例子來說, 這是一個最適合的工具了
最早的readability應該是arc90這人開源出來的, 最早應該是javascript的版本, 但就算你不是用javascript, 它老早也被翻唱成其他語言的版本了, 像是:
- Python - python-readability
- Node.js - node.js readability
- Java - JReadability 和 snacktory
- Go - go-readability
結巴 jieba
結巴 jieba 是一個用在做中文分詞的工具, 英文每個單詞都是用空白分開的, 但中文就不是那麼回事了, 結巴 jieba 可以幫忙作掉這部份的工作, 這可以拿來做文章分析或是找關鍵字用
一樣有好幾種語言的版本 - Java, C++, Node.js, Erlang, R, iOS, PHP, C#, Go (參照結巴的說明內文), 算蠻齊全的了
範例二 : 抓取Bilibili的視訊檔位址
這個範例稍微做了點弊, 但還是從頭把分析過程來講一下好了
Bilibili視頻網頁長得就像這樣: 範例 - http://www.bilibili.com/video/av6467776/
先簡單的從網址猜一下….“av6467776"應該是某個ID之類的東西, 再進一步, ID可能就是這個"6467776”
接下來我們就需要借助一下Chrome的"開發人員工具", 這是一個強大也重要的工具, 不要只傻傻的用View source而已, View source能看到的也只有原始HTML的內容
開了網頁後, 用Ctrl+Shift+I (windows)或是Cmd+Opt+I (mac)打開他, 打開後先選到elements, 像這樣:
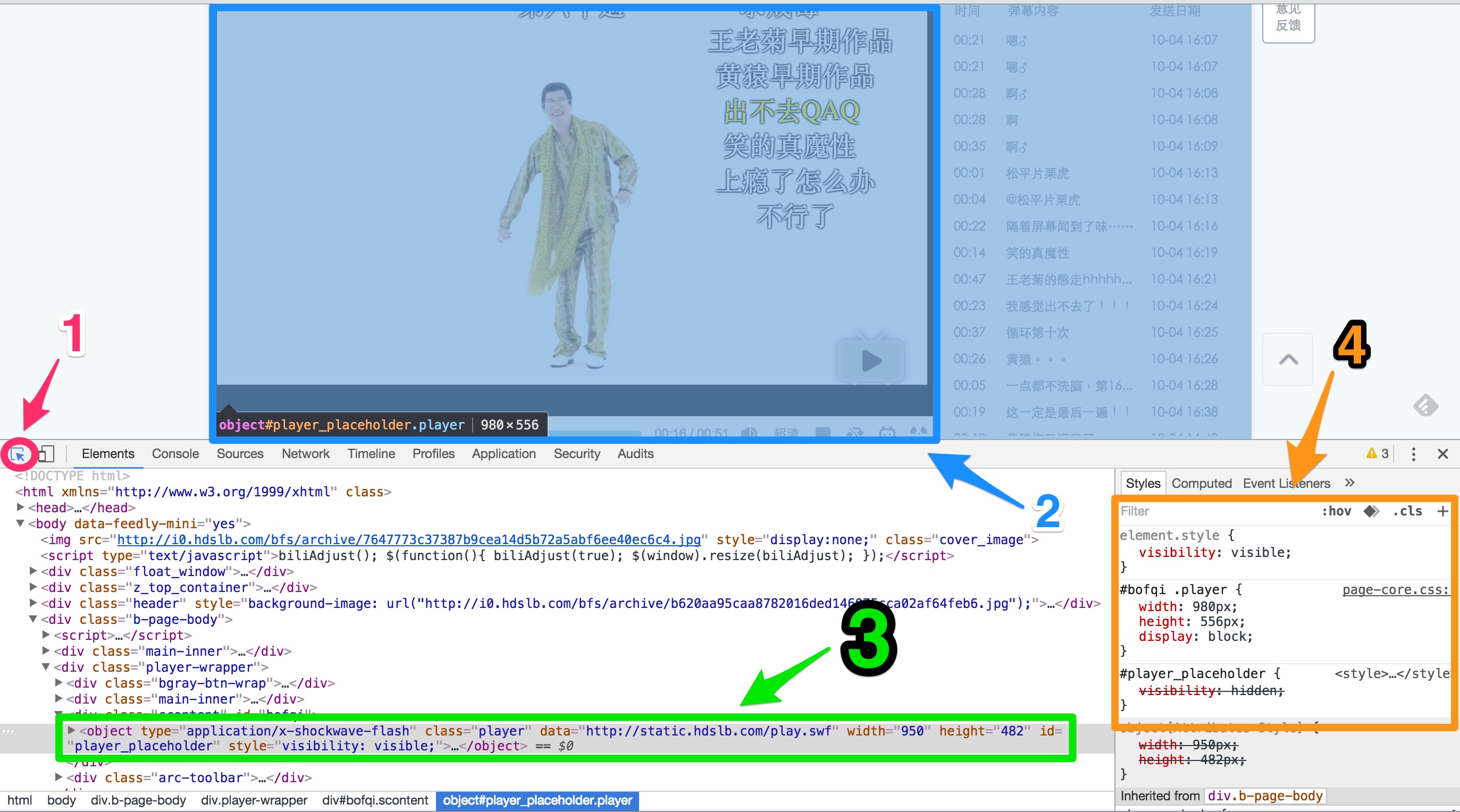
這邊標示了四個部分, 先點選了1, 再用滑鼠游標點你想知道的元件(以這邊來說是那個視訊框 2 的地方), 然後他就會幫你跳到相關的HTML位置(如3), 而4所標示出的是css屬性
把object這部份點開, 果然, 在flashvars那邊我們可以找到"cid=10519268&aid=6467776&pre_ad=0"這樣的字串, 表示"6467776"的確是某種叫aid的東西, 但, 這不代表找到結案了!! 我們再用curl檢查一下:
curl http://www.bilibili.com/video/av6467776/ --compressed
抓原始的html檔來比對一下(可以把這指令的輸出存成檔案在來看會方便點), 怎麼沒"object"這標籤呀?到哪去了?可見剛剛那段html是某段javascript去產生的
再回頭看DevTools上object那段, 可以發現它是一個div包起來的, 這div的class是scontent, id是bofqi, 再回頭去看原始的HTML, 整段也只有一個這樣的block, 內容是這樣:
<div class="scontent" id="bofqi">
<div id='player_placeholder' class='player'></div>
<script type='text/javascript'>EmbedPlayer('player', "http://static.hdslb.com/play.swf", "cid=10519268&aid=6467776&pre_ad=0");</script>
</div>
OK, 這邊就很容易可以確定從scontent這區塊就可以找到兩個id - aid和cid , 但這能做什麼用? 還不知道
接著切換到Network那邊去, 然後再重新整理一下頁面:
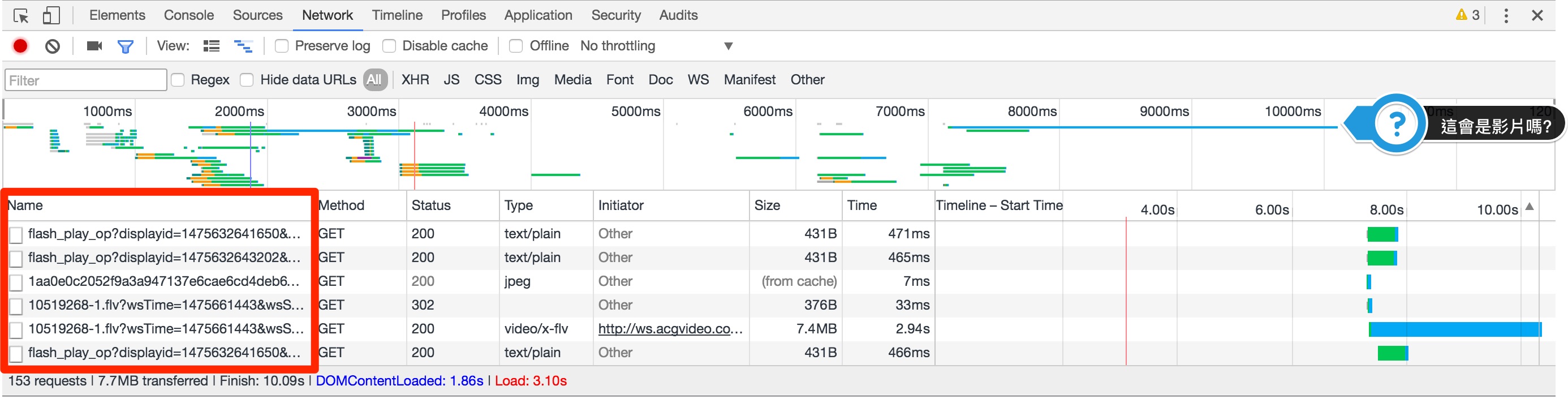
左下角的部分是瀏覽器在畫出這個頁面所載入的內容跟檔案, 一開使用時序排序的, 當然你可以用其他方式排序, 這邊就是可以挖寶的地方了
先看到上面那一堆長長短短的線, 這是瀏覽器載入檔案的時間線, 點選這邊可以只看特定時間區間的部分, 最後面可以發現有一條長長的藍線, 那可能就是視訊檔了(因為通常較大), 因此我們可知這視訊檔的URL是
http://61.221.181.215/ws.acgvideo.com/3/46/10519268-1.flv?wsTime=1475663926&wsSecret2=893ba83b8f13d8700d2ae0cddab96c55&oi=3699654085&rate=0&wshc_tag=0&wsts_tag=57f467b8&wsid_tag=dc843dc5&wsiphost=ipdbm
但這串怎麼來的, 依我們手上只有兩個id的資訊是拼湊不起來的, 它一定從某個地方由這兩個id轉換出來的(合理的猜測), 因此, 我們可以再把aid, cid拿去搜尋檔案(點選檔案列表那區塊, 按ctrl-f或command-f開搜尋框)
一個個看, 找出可能的檔案, 由於aid可以找出22個結果而cid只有10個, 從cid開始找起會比較簡單點, 這邊篩選出幾個可能性:
- http://interface.bilibili.com/player?id=cid:10519268&aid=6467776 - 回傳是一個xml, 有一些相關資訊, 但沒影片位址
- http://interface.bilibili.com/playurl?accel=1&cid=10519268&player=1&ts=1475635126&sign=e1e2ae9d2d34e4be94f46f77a4a107ce - 從這回傳裡面有個durl > url, 跟上面url比對, 似乎就是他了, 後面再來講這段
- http://comment.bilibili.com/playtag,10519268 - 這應該是"看过该视频的还喜欢"裡的內容
- http://comment.bilibili.com/10519268.xml - 喔喔喔, 看起來這就是彈幕檔喔!
- http://comment.bilibili.com/recommendnew,6467776 - 這似乎是推薦視頻的內容
- http://api.bilibili.com/x/tag/archive/tags?jsonp=jsonp&aid=6467776&nomid=1 - 看起來這是tag
看來, 2 應該就是我們所要的了, 不過這邊有兩個麻煩, 一個是…我討厭XML!!!!!不過這好像還好, 似乎有個HTML5版本, 點點看好了, 果不其然, 發現另一個:
https://interface.bilibili.com/playurl?cid=10519268&appkey=6f90a59ac58a4123&otype=json&type=flv&quality=3&sign=571f239a0a3d4c304e8ea0e0f255992a
表示我們是可以用otype=json來抓取json格式的, 但後面這個更麻煩了, 那個sign是什麼東西? 從他有個appkey來看, 合理的猜測, 他是某種API的signature, 通常這種東西的規則是把所有的參數先依名字排序成新的query string, 加上某個secret, 再算出他的MD5即是他的sign
但如果真是這樣, 這下有點麻煩, 到哪裡找這個secret, 不過凡走過必有痕跡, 這串既然是由瀏覽器端產生的, 那應該會在哪裡找到點線索, 或許可以先用appkey的內容去每個javascript檔案搜尋吧
不過, 不出所料, 找不到, 那, 還有一個可能性, 它寫在flash內, 從上面抓到的資訊來看, 他的flash檔案應該是: http://static.hdslb.com/play.swf
可以把它抓回來反編譯(decompile), 有個工具叫JPEX Flash decompiler的, 可以做到這件事
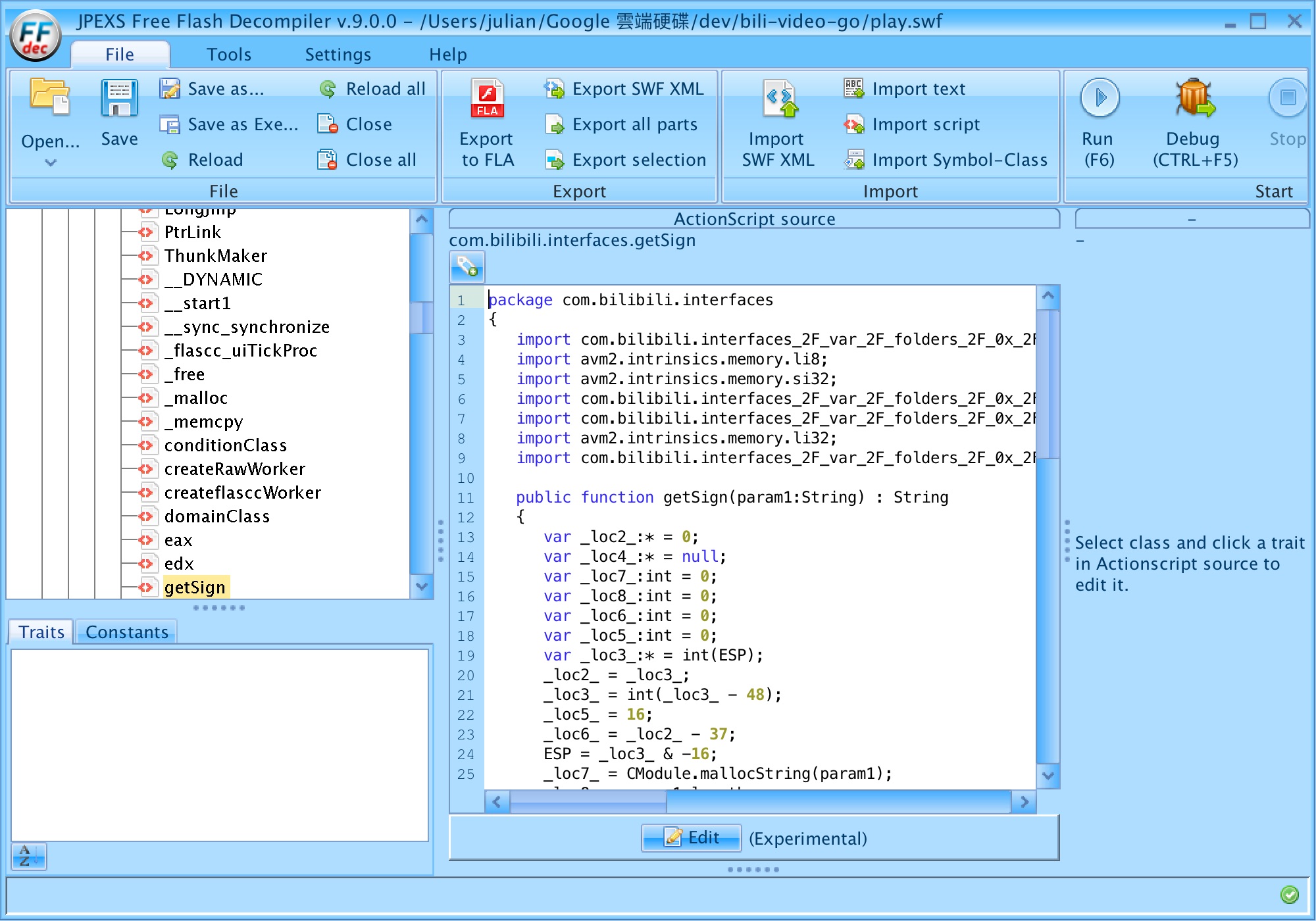
在script裡面有它的程式原始碼, 應該可以在裡面找到, 不過有點辛苦, 因為你也沒辦法從appkey找到那個secret, 這邊直接跳轉答案, 應該就如同截圖所示是"com.bilibili.interfaces.getSign"這邊, 只是被混淆到很難看, 看得很頭痛, 會短命的
理論上, 把這段源碼翻譯一遍後應該就解決了, 但一來我看不太懂action script, 二來我實在懶得看, 想偷懶, 有沒作弊的方法? 凡走過必留下痕跡嘛, 一定還會有前人走過這條路, 所以直接把"6f90a59ac58a4123"這串appkey拿去搜尋, 果然, 找到secret了, 寫個程式驗證一下, 果然是沒錯的
範例三: 楓林網
楓林網是一個非法的電視劇來源, 有相當齊全的電視劇內容, 我這個是之前寫的一個工具了, 可以把一整部劇可以抓回本地端, 原始碼跟使用方法在這:
這邊就不再說明怎麼使用它了, 主要著重它是怎做出來的, 這一個跟上面幾個不一樣的地方在於我是用nodejs寫的, 之所以用nodejs是有原因的, 後面再解釋, 主要的程式碼在88.js
楓林網的電視劇集的網址長成這樣: http://8drama.com/178372/ , 當然178372又是ID了, 但它裡面所有的東西ID長得都是一個樣, 一整部劇跟單一集的ID都是同一個格式, 所以是無法從ID判斷出他是哪類
一樣打開Chrome DevTools, 點選到每一集的列表區塊, 我們可以發現在"“裡面的可以找到每一集的URL, 而他的格式都是http://8drama.com/(ID), 所以我們可以輕易的用regular expression分辨出來
接下來就要掃每一集的內容把影片檔找出來了
當然可以用前面的方法試試看, 不過那方法在這邊沒啥用, 因為這邊影片的網址編碼是用好多亂七八糟的javascript堆積起來, 沒記錯的話, 我是從video.js找到線索的(這有點時間之前做的了, 有點沒印象了)
所以該怎麼面對那一大段javascript的code呢? 這就是我這工具為何選nodejs的原因了, 抄過來就好了!!! 去除掉跟瀏覽器相關的部分, 它就是不折不扣nodejs可以跑的程式碼, 所以這也就是88.js一些怪怪程式碼的由來
除了這版本外, 我本來也有想要做一個Java的版本, 做了一半, 用Java也是可以用類似的技巧, 不過就得要導入Javascript的runtime了, 而我採用的是Mozilla Rhino
更進階一點的
做爬蟲大部分的時間都是要跟html, javascript, css這類的東西搏鬥, 但其實很多東西本來就是原本瀏覽器就會處理的, 因此如果可以直接用瀏覽器或甚至是WebKit來處理, 可以處理的事應該就會多一點, 這時候就可以利用所謂的Headless browser來簡化, 這種東西本來是用在網頁自動化測試的, 不過, 用在這應用也一樣強大, 這類的解決方案有:
關於Phantomjs的應用, 我很久之前已經有寫過一篇了:
Android上呢?
Java上, 大多是用jsoup來解析html的, 像我之前這篇:
當然應該也是可以用Webkit/WebView做成headless的解決方案, 不過這部份我目前還沒試過, 留待以後有機會再試吧